Automated essay scoring using efficient transformer-based language models

Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written. Large pretrained transformer-based language models have dominated the current state-of-the-art in many NLP tasks, however, the computational requirements of these models make them expensive to deploy in practice. The goal of this paper is to challenge the paradigm in NLP that bigger is better when it comes to AES. To do this, we evaluate the performance of several fine-tuned pretrained NLP models with a modest number of parameters on an AES dataset. By ensembling our models, we achieve excellent results with fewer parameters than most pretrained transformer-based models.

Christopher M. Ormerod
Akanksha Malhotra
Amir Jafari


Related Research
Gpt-3 models are poor few-shot learners in the biomedical domain, short-answer scoring with ensembles of pretrained language models, comparing test sets with item response theory, nlp-based decision support system for examination of eligibility criteria from securities prospectuses at the german central bank, edubert: pretrained deep language models for learning analytics, pum at semeval-2020 task 12: aggregation of transformer-based models' features for offensive language recognition, language models are good pathologists: using attention-based sequence reduction and text-pretrained transformers for efficient wsi classification.
Please sign up or login with your details
Generation Overview
AI Generator calls
AI Chat messages
Genius Mode messages
Genius Mode images
AD-free experience
Private images
- Includes 500 AI Image generations, 1750 AI Chat Messages, 60 Genius Mode Messages and 60 Genius Mode Images per month. If you go over any of these limits, you will be charged an extra $5 for that group.
- For example: if you go over 500 AI images, but stay within the limits for AI Chat and Genius Mode, you'll be charged $5 per additional 500 AI Image generations.
- Includes 100 AI Image generations and 300 AI Chat Messages. If you go over any of these limits, you will have to pay as you go.
- For example: if you go over 100 AI images, but stay within the limits for AI Chat, you'll have to reload on credits to generate more images. Choose from $5 - $1000. You'll only pay for what you use.
Out of credits
Refill your membership to continue using DeepAI
Subscribe to the PwC Newsletter
Join the community, edit social preview.

Add a new code entry for this paper
Remove a code repository from this paper, mark the official implementation from paper authors, add a new evaluation result row.
- AUTOMATED ESSAY SCORING
- BIG-BENCH MACHINE LEARNING
- TEXT-CLASSIFICATION
- TEXT CLASSIFICATION
Remove a task

Add a method
- LOGISTIC REGRESSION
Remove a method
- LOGISTIC REGRESSION -
Edit Datasets
Automated essay scoring using transformer models.
13 Oct 2021 · Sabrina Ludwig , Christian Mayer , Christopher Hansen , Kerstin Eilers , Steffen Brandt · Edit social preview
Automated essay scoring (AES) is gaining increasing attention in the education sector as it significantly reduces the burden of manual scoring and allows ad hoc feedback for learners. Natural language processing based on machine learning has been shown to be particularly suitable for text classification and AES. While many machine-learning approaches for AES still rely on a bag-of-words (BOW) approach, we consider a transformer-based approach in this paper, compare its performance to a logistic regression model based on the BOW approach and discuss their differences. The analysis is based on 2,088 email responses to a problem-solving task, that were manually labeled in terms of politeness. Both transformer models considered in that analysis outperformed without any hyper-parameter tuning the regression-based model. We argue that for AES tasks such as politeness classification, the transformer-based approach has significant advantages, while a BOW approach suffers from not taking word order into account and reducing the words to their stem. Further, we show how such models can help increase the accuracy of human raters, and we provide a detailed instruction on how to implement transformer-based models for one's own purpose.
Code Edit Add Remove Mark official
Tasks edit add remove, datasets edit, results from the paper edit add remove, methods edit add remove.
Automated Pipeline for Multi-lingual Automated Essay Scoring with ReaderBench
- Published: 01 April 2024
Cite this article
- Stefan Ruseti ORCID: orcid.org/0000-0002-0380-6814 1 ,
- Ionut Paraschiv 1 ,
- Mihai Dascalu ORCID: orcid.org/0000-0002-4815-9227 1 , 2 &
- Danielle S. McNamara 3
Automated Essay Scoring (AES) is a well-studied problem in Natural Language Processing applied in education. Solutions vary from handcrafted linguistic features to large Transformer-based models, implying a significant effort in feature extraction and model implementation. We introduce a novel Automated Machine Learning (AutoML) pipeline integrated into the ReaderBench platform designed to simplify the process of training AES models by automating both feature extraction and architecture tuning for any multilingual dataset uploaded by the user. The dataset must contain a list of texts, each with potentially multiple annotations, either scores or labels. The platform includes traditional ML models relying on linguistic features and a hybrid approach combining Transformer-based architectures with the previous features. Our method was evaluated on three publicly available datasets in three different languages (English, Portuguese, and French) and compared with the best currently published results on these datasets. Our automated approach achieved comparable results to state-of-the-art models on two datasets, while it obtained the best performance on the third corpus in Portuguese.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
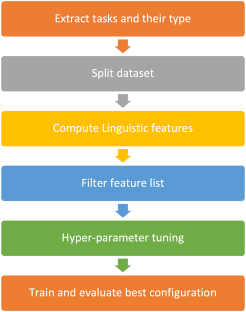
Data Availability
All three datasets used for evaluation are publicly available: ASAP - https://www.kaggle.com/c/asap-aes ; Essay-BR - https://github.com/lplnufpi/essay-br ; French FakeNews https://huggingface.co/datasets/readerbench/fakenews-climate-fr l .
Code Availability
The code repository is publicly available on GitHub https://github.com/readerbench/ReaderBenchAPI . The platform can be accessed at https://readerbench.com .
https://h2o.ai/platform/h2o-automl/
https://cloud.google.com/automl/
http://www.cs.ubc.ca/labs/beta/Projects/autoweka/
https://autokeras.com/
https://github.com/readerbench/ReaderBenchAPI
https://readerbench.com
https://github.com/readerbench/ReaderBench/wiki/Textual-Complexity-Indices
https://www.kaggle.com/competitions/asap-aes/overview
https://paperswithcode.com/sota/automated-essay-scoring-on-asap
https://scikit-learn.org/stable/modules/generated/sklearn.utils.class_weight .compute_class_weight.html.
Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. (2019). Optuna: A next-generation hyperparameter optimization framework. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining
Amorim, E., Canc¸ado, M., & Veloso, A. (2018). Automated essay scoring in the presence of biased ratings. Proceedings of the 2018 conference of the north american chapter of the association for computational linguistics:Human language technologies, volume 1 (long papers) (pp. 229–237).
Ayoub, G. (2023). Pyphen Retrieved from https://pypi.org/project/pyphen/ .
Burstein, J., Kukich, K., Wolff, S., Lu, C., & Chodorow, M. (1998, April). Computer analysis of essays. In NCME symposium on automated scoring .
Chen, T., & Guestrin, C. (2016). Xgboost: A scalable tree boosting system. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785–794).
Cozma, M., Butnaru, A., & Ionescu, R. T. (2018). Automated essay scoring with string kernels and word embeddings. Proceedings of the 56th annual meeting of the association for computational linguistics (Volume 2: Short papers) (pp. 503–509).
Crossley, S. A., Kyle, K., & McNamara, D. S. (2015). To aggregate or not? Linguistic features in automatic essay scoring and feedback systems. Grantee Submission , 8 (1).
Crossley, S. A., Kyle, K., & McNamara, D. S. (2016). The tool for the automatic analysis of text cohesion (taaco): Automatic assessment of local, global, and text cohesion. Behavior Research Methods , 48 , 1227–1237.
Article Google Scholar
Dascalu, M., Dessus, P., Trausan-Matu, S., Bianco, M., & Nardy, A. (2013). Readerbench - an environment for analyzing textual complexity, reading strategies and collaboration. In International Conference on Artificial Intelligence in Education (AIED 2013) (p. 379–388). Springer.
Dascalu, M., Dessus, P., Bianco, M., Trausan-Matu, S., & Nardy, A. (2014). Mining texts, learner productions and strategies with ReaderBench. In A. Peña-Ayala (Ed.), Educational Data Mining: Applications and Trends (pp. 345–377). Springer.
Dascalu, M., McNamara, D. S., Trausan-Matu, S., & Allen, L. (2018). Cohesion network analysis of cscl participation. Behavior Research Methods , 50 (2), 604–619. https://doi.org/10.3758/s13428-017-0888-4 .
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, June). BERT: Pretraining of deep bidirectional transformers for language understanding. Proceedings of the 2019 Conference of the North American chapter of the Association for Computational Linguistics: Human language technologies, volume 1 (long and short papers) (pp. 4171–4186). Minneapolis, Minnesota: Association for Computational Linguistics.
Explosion (2023). spaCy . Retrieved from https://spacy.io .
Fellbaum, C. (2005). Wordnet(s). In K. Brown (Ed.), Encyclopedia of language and linguistics (2nd ed., Vol. 13, pp. 665–670). Elsevier.
Feurer, M., Klein, A., Eggensperger, K., Springenberg, J., Blum, M., & Hutter, F. (2015). Efficient and robust automated machine learning. Advances in neural information processing systems , 28 .
Foltz, P. W., Lochbaum, K. E., & Rosenstein, M. R. (2017). Automated writing evaluation: Defining the territory. Assessing Writing , 34 , 9–22.
Google Scholar
Fonseca, E., Medeiros, I., Kamikawachi, D., & Bokan, A. (2018). Automatically grading Brazilian student essays. In Computational processing of the Portuguese language. September 24–26, 2018 (pp. 170–179).
Graesser, A. C., McNamara, D. S., Louwerse, M. M., & Cai, Z. (2004). Coh-Metrix: Analysis of text on cohesion and language. Behavior Research Methods Instruments & Computers , 36 (2), 193–202.
He, X., Zhao, K., & Chu, X. (2021). AutoML: A survey of the state-of-the-art. Knowledge-Based Systems , 212 , 106622. Retrieved from https://www.sciencedirect.com/science/article/pii/S0950705120307516 https://doi.org/10.1016/j.knosys.2020.106622 .
Hutter, F., Kotthoff, L., & Vanschoren, J. (2019). Automated machine learning: Methods, systems, challenges . Springer Nature.
Jeon, S., & Strube, M. (2021). Countering the influence of essay length in neural essay scoring. Proceedings of the second workshop on simple and efficient natural language processing (pp. 32–38).
Jin, H., Song, Q., & Hu, X. (2019). Auto-keras: An efficient neural architecture search system. Proceedings of the 25th acm sigkdd international conference on knowledge discovery & data mining (pp. 1946–1956).
Jordan, M. I., & Mitchell, T. M. (2015). Machine learning: Trends, perspectives, and prospects. Science , 349 (6245), 255–260.
Article MathSciNet Google Scholar
Kyle, K., Crossley, S., & Berger, C. (2018). The tool for the automatic analysis of lexical sophistication (taales): Version 2.0. Behavior Research Methods , 50 , 1030–1046.
Landauer, T., Laham, D., & Foltz, P. (2000). The intelligent essay assessor. Intelligent Systems IEEE , 15 , 09.
LeDell, E., & Poirier, S. (2020). H2o automl: Scalable automatic machine learning. Proceedings of the automl workshop at icml (Vol. 2020).
Li, L., Jamieson, K., Rostamizadeh, A., Gonina, E., Hardt, M., Recht, B., & Talwalkar, A. (2018). Massively parallel hyperparameter tuning. arXiv preprint arXiv:1810.05934 , 5 .
Liaw, R., Liang, E., Nishihara, R., Moritz, P., Gonzalez, J. E., & Stoica, I. (2018). Tune: A research platform for distributed model selection and training. arXiv preprint arXiv:1807.05118 .
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 .
Mangal, D., & Sharma, D. K. (2020, June). Fake news detection with integration of embedded text cues and image features. In 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (trends and future directions) (ICRITO) (pp. 68–72). IEEE.
Marinho, J., Anchiˆeta, R., & Moura, R. (2022). Essay-BR: a Brazilian corpus to automatic essay scoring task. Journal of Information and Data Management , 13 (1), 65–76. Retrieved from https://sol.sbc.org.br/journals/index.php/jidm/article/view/2340.10.5753/jidm.2022.2340 .
Martin, L., Muller, B., Suárez, P. J. O., Dupont, Y., Romary, L., de La Clergerie, É. V., Seddah, D., & Sagot, B. (2020). Camembert: a tasty French language model. Proceedings of the 58th annual meeting of the association for computational linguistics
McNamara, D. S., Crossley, S. A., Roscoe, R. D., Allen, L. K., & Dai, J. (2015). A hierarchical classification approach to automated essay scoring. Assessing Writing , 23 , 35–59.
Meddeb, P., Ruseti, S., Dascalu, M., Terian, S. M., & Travadel, S. (2022). Counteracting French fake news on climate change using language models. Sustainability , 14 (18), 11724.
Mridha, M. F., Keya, A. J., Hamid, M. A., Monowar, M. M., & Rahman, M. S. (2021). A comprehensive review on fake news detection with deep learning. Ieee Access: Practical Innovations, Open Solutions , 9 , 156151–156170.
Olson, R. S., & Moore, J. H. (2016). Tpot: A tree-based pipeline optimization tool for automating machine learning. Workshop on automatic machine learning (pp. 66–74).
Page, E. B. (2003). The imminence of grading essays by computer—25 years later. The Journal of Technology Learning and Assessment , 2 (1), 1–19.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., & Vanderplas, J. (2011). Scikit-learn: Machine learning in Python. The Journal of Machine Learning Research , 12 , 2825–2830.
MathSciNet Google Scholar
Plonska, A., & Plonski, P. (2021). Mljar: State-of-the-art automated machine learning framework for tabular data. version 0.10.3 L apy, Poland: MLJAR. Retrieved from https://github.com/mljar/mljar-supervised .
Scao, T. L., Fan, A., Akiki, C., Pavlick, E., Ilić, S., Hesslow, D., Castagné, R., Luccioni, A. S., Yvon, F., Gallé, M., & Tow, J. (2022). Bloom: A 176B-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100 .
Shermis, M. D. (2014). State-of-the-art automated essay scoring: Competition, results, and future directions from a United States demonstration. Assessing Writing , 20 , 53–76.
Shu, K., Mahudeswaran, D., Wang, S., & Liu, H. (2020, May). Hierarchical propagation networks for fake news detection: Investigation and exploitation. In Proceedings of the International AAAI Conference on Web and Social Media (Vol. 14, pp. 626–637).
Souza, F., Nogueira, R., & Lotufo, R. (2020). BERTimbau: Pretrained BERT models for Brazilian Portuguese. 9th Brazilian conference on intelligent systems, BRACIS, Rio Grande do Sul, Brazil
Stab, C., & Gurevych, I. (2014). Identifying argumentative discourse structures in persuasive essays. https://doi.org/10.3115/v1/D14-1006 .
Tausczik, Y. R., & Pennebaker, J. W. (2010). The psychological meaning of words: LIWC and computerized text analysis methods. Journal of Language and Social Psychology , 29 (1), 24–54.
Thornton, C., Hutter, F., Hoos, H. H., & Leyton-Brown, K. (2013). Auto-weka: Combined selection and hyperparameter optimization of classification algorithms. Proceedings of the 19th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 847–855).
Tsiakmaki, M., Kostopoulos, G., Kotsiantis, S., & Ragos, O. (2020). Implementing AutoML in educational data mining for prediction tasks. Applied Sciences , 10 (1). Retrieved from https://www.mdpi.com/2076-3417/10/1/9010.3390/app10010090 .
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems , 30 .
Wang, Y., Wang, C., Li, R., & Lin, H. (2022). On the use of bert for auto-mated essay scoring: Joint learning of multi-scale essay representation. Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies (pp. 3416–3425).
Download references
Acknowledgements
We would like to thank Emanuel Tertes and Pavel Betiu who supported us in developing the new interface for ReaderBench.
This work was supported by a grant from the Ministry of Research, Innovation and Digitalization, project CloudPrecis “Increasing UPB’s research capacity in Cloud technologies and massive data processing”, Contract Number 344/390020/06.09.2021, MySMIS code: 124812, within POC. The research reported here was also supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R305A180261 to Arizona State University. The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Department of Education.
Author information
Authors and affiliations.
Computer Science and Engineering Department, University Politehnica of Bucharest, Bucharest, Romania
Stefan Ruseti, Ionut Paraschiv & Mihai Dascalu
Academy of Romanian Scientists, Bucharest, Romania
Mihai Dascalu
Department of Psychology, Arizona State University, Tempe, AZ, USA
Danielle S. McNamara
You can also search for this author in PubMed Google Scholar
Contributions
All authors contributed to the study’s conception and design. Material preparation, data collection, and analysis were performed by Stefan Ruseti. The first draft of the manuscript was written by Ionut Paraschiv and Stefan Ruseti, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Correspondence to Mihai Dascalu .
Ethics declarations
Ethics approval.
Not applicable.
Consent to Participate
Consent for publication, conflict of interest/competing interests.
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Ruseti, S., Paraschiv, I., Dascalu, M. et al. Automated Pipeline for Multi-lingual Automated Essay Scoring with ReaderBench. Int J Artif Intell Educ (2024). https://doi.org/10.1007/s40593-024-00402-4
Download citation
Accepted : 13 March 2024
Published : 01 April 2024
DOI : https://doi.org/10.1007/s40593-024-00402-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Automated essay scoring
- Natural language processing
- Automated machine learning
- Linguistic features
- Transformer-based models
Advertisement
- Find a journal
- Publish with us
- Track your research
Data Augmentation for Automated Essay Scoring using Transformer Models
Automated essay scoring is one of the most important problem in Natural Language Processing. It has been explored for a number of years, and it remains partially solved. In addition to its economic and educational usefulness, it presents research problems. Transfer learning has proved to be beneficial in NLP. Data augmentation techniques have also helped build state-of-the-art models for automated essay scoring. Many works in the past have attempted to solve this problem by using RNNs, LSTMs, etc. This work examines the transformer models like BERT, RoBERTa, etc. We empirically demonstrate the effectiveness of transformer models and data augmentation for automated essay grading across many topics using a single model.
Index Terms:
I introduction.
As a result of the COVID-19 pandemic, online schooling system became necessary. From elementary schools to colleges, almost all educational institutions have adopted the online education system. The majority of automated evaluations are accessible for multiple-choice questions, but evaluating short and essay type responses remains unsolved since, unlike multiple-choice questions, there is no one correct solution for these kind of questions. It is an essential education-related application that employs NLP and machine learning methodologies. It is difficult to evaluate essays using basic computer languages and methods such as pattern matching and language processing.
Among the most important pedagogical uses of NLP is automated essay scoring (AES), the technique of using a system to score short and essay type questions without manual assistance. Initiated by Page’s [1966] groundbreaking work on the Project Essay Grader system, this area of study has seen continuous activity ever since. The bulk of AES research has been on holistic scoring, which provides a quantitative summary of an essay’s quality in a single number. At least two factors contribute to this concentration of effort. To begin with, learning-based holistic scoring systems may make use of publically accessible corpora that have been manually annotated with holistic scores. Second, there is a market for holistic scoring algorithms because they may streamline the arduous process of manually evaluating the millions of essays for tests like GRE, IELTS, SAT.
Past research on automated essay grading has included training models for essays for which training data is available and those models are topic specific. This model is trained on all the topics thus could be used for assessment of essays of all those topics without training model specific for each topic. This would be useful in the scenario where we did not have enough data to train a model that is specific to a particular topic, but we still needed to evaluate essays on that topic. Therefore, in order to assess them, We may utilize a model that has been trained on essays on a variety of topics and a tiny amount of data on the topic for which we need to develop a model, which will then be fine-tuned using the limited data available on the subject being assessed.
This paper is organized as follows: In Section II, we explore pertinent prior research on automated essay scoring; in Section III, we cover experimental setup; and in Section IV, we describe our methodology for augmenting essay data. In Section V, we give the results and analysis of the automated essay grading model. Section VI comprises of conclusion and future work for Automated Essay Scoring.
II Related Works
Project Essay Grader (PEG) by [ 1 ] started the research on Automated essay scoring. Shermis (2001) [ 2 ] improved the PEG system by incorporating the grammatical features as well in the evaluation. Around the turn of century, great majority of essay scoring systems used conventional methods like latent semantic analysis by Foltz (1999) [ 3 ] , as pattern matching and statistical analysis like Bayesian Essay Test Scoring System by [ 4 ] . These systems employ natural language processing (NLP) approaches that concentrate on grammar, content to determine an essay’s score.
Multiple studies studied AES systems, from the earliest to the most recent. Blood (2011) [ 6 ] reviewed the PEG literature from 1984 to 2010, it has discussed just broad features of AES systems, such as ethical considerations and system performance. However, they have not addressed the implementation aspect, nor has a comparison research been conducted, nor have the real problems of AES systems been highlighted.
After 2014, Automated grading systems like as those by [ 5 ] and others, employed deep learning approaches to induce syntactic and semantic characteristics, producing greater outcomes than previous systems. Burrows (2015) [ 7 ] reviewed on aspects, including datasets, NLP approaches, model construction, model grading, model assessment, and model efficacy. Ke (2019) [ 8 ] , Hussein (2019) [ 9 ] and Klebanov (2020) [ 10 ] offered overview of the AES system.
Ramesh (2019) [ 19 ] offered us a comprehensive summary of all accessible datasets and the machine learning algorithms used to grade essays. Recently Park (2022) [ 23 ] tried using GAN’s for evaluation of essays. Our motivation of using Deep-learning models for automated essay scoring was due to recent study by Elijah (2020) [ 20 ] and Wang (2022) [ 25 ] , it showed us that using BERT based models it certainly improves the accuracy of the Automated essay scoring.
Jong (2022) [ 24 ] demonstrated the effectiveness of data augmentation techniques on automated essay scoring. Ludwig (2021) [ 21 ] , Ormerod (2021) [ 22 ] and Sethi (2022) [ 26 ] examined the transformer based models on automated essay scoring, these recent findings prompted us to test our data augmentation strategy on transformer-based models for automated essay grading.
III Experimental Setup
For the purpose of this study, we will constrain the study and experiments to ASPA1 dataset. The Automated Student Assessment Prize(ASAP1) 1 1 1 https://www.kaggle.com/c/asap-aes corpus was released as part of a Kaggle competition in 2012. This corpus is used for holistic scoring of essays and consists of essays from eight topics with around 3000 essays on each of the topic. Each topic had a different scoring method, so, we normalized of each essay score from 0 to 10 so that we could train all the data together.
We run our experiments using the BERT, RoBERTa, ALBERT, DistilBERT, XLM-RoBERTa, implementation available in the Simple Transformers library provided by Thilina Rajapakse 2 2 2 https://simpletransformers.ai/ . We run our experiment on Google Colab. For baseline trials, we consider the essays which are not supplemented with our data augmentation technique and trained on models based on Transformers.
During training, we additionally fine-tuned our parameters by adjusting the parameters like learning rate, weight decay rate, etc. For the purpose of evaluating our model, we will use the accuracy score measure given by the Scikit library 3 3 3 https://scikit-learn.org/stable/index.html . Since we are approaching our issue as a multi-label classification, the accuracy metric is often used to evaluate multi-label classifications.

IV Methodology
Iv-a large pre-trained models.
The models which we used for training are based on the Transformers(Fig. 1 ) architecture introduced by [ 11 ] . The Transformer’s architecture follows an encoder-decoder structure.
Given below is the brief description of each of the model which we are using for training:
IV-A 1 BERT
The Bidirectional Encoder Representations (BERT) introduced by [ 12 ] is a deep learning model in which every output element is linked to every input element and the weightings between them are dynamically determined depending on their relationship. BERT is pre-trained on two tasks: Masked Language Modeling and Next Sentence Prediction.
IV-A 2 RoBERTa
Robustly optimized BERT Pre-training Approach (RoBERTa) introduced by [ 13 ] builds upon BERT’s language masking method, in which the system learns to anticipate purposely masked bits of text inside unannotated language samples. RoBERTa changes critical hyperparameters in BERT, such as eliminating BERT’s next-sentence pretraining target and training with much bigger mini-batches and learning rates. This enables RoBERTa to outperform BERT at the masked language modeling goal and improves the performance of subsequent tasks.
IV-A 3 ALBERT
ALBERT, introduced by [ 14 ] is an encoder-decoder based model with self-attention at the encoder and attention to encoder outputs at the decoder end. It is a modified version of BERT and it stands for ”A Lite BERT”. It builds on parameter sharing, embedding factorization, and sentence order prediction(SOP).
IV-A 4 DistilBERT
DistilBERT, introduced by [ 15 ] aims to optimize the training by reducing the size of BERT and increasing the speed of BERT—all while trying to retain as much performance as possible. Specifically, DistilBERT is smaller than the original BERT-base model, is faster than it, and retains its functionality.
IV-A 5 XLM-RoBERTa
XLM-RoBERTa, Unsupervised Cross-lingual Representation Learning at Scale, introduced by [ 16 ] is a scaled cross-lingual sentence encoder. It is trained on 2.5 TB of data across 100 languages filtered from Common Crawl. XLM-RoBERTa achieves state-of-the-art results on multiple cross-lingual benchmarks.

IV-B Data Augmentation
Researchers have attempted to use several RNNs and LSTMs as training models for automated essay scoring. However, the fundamental disadvantage of such models is that they are topic-specific, and we want to construct an automated essay scoring system that can perform well not just on subjects for which we have an abundance of data but also on subjects for which we have a limited amount of data. Now, we want to augment the essay so that it can accurately assess a essay on a different topic for which we have a very small amount of data.
When training a model, we add each essay with its topic at certain intervals. We are including essay topics after an interval because essays are lengthy, and if we train only on essays, the trained model will be topic-specific. In order to construct a more robust model, we append the essay’s subject to each essay so that the training model may learn the relationship between the essay’s topic and the essay itself. This is so that it accurately grades essays on a different topic, which we are using majorly for fine-tuning since we have very little data available to us and we can not train topic-specific models using this less amount of data.
We cannot add a complete topic to an essay because sometimes essay topics are quite large. Hence, we summarize the topics of essays using the summarization pipeline provided by [ 17 ] implementation of BART, which was introduced by [ 18 ] . Now, the second issue is, after how many lines should we put the subject for optimum precision? We conducted extensive data trials by inserting them at different places.
After a comprehensive investigation of several transformer-based models and essay subject insertions, we determined that the tenth place is optimal for inserting the topic. It implies that after every tenth line, a summary of the subject is added to the essay. It may be due to the fact that the model struggles with lengthy text classification; thus, we keep this in mind by inserting topics at regular intervals. Fig. 2 shows the complete data augmentation of essay. Now that the topic has been inserted into the essay, the data is modified for training transformer models. The next section provides a study of modified essays.
V Results and Analysis
The ASAP1 dataset contains around 17K essays on eight topics. We are using that data for pre-training by augmenting those essays using our technique. For fine tuning For research and testing purposes, we used this dataset . This dataset consists of 1241 essays on four subjects. We fine-tuned and tested our models on each subject individually. We used around two-thirds of the above mentioned dataset for training and fine-tuning, and the remaining one-third for testing.
We followed a very simple yet state-of-the-art modeling technique for multi-label classification using transformer models. We bucketed scores into each interval class, resulting in 11 buckets. These 11 classes correspond to a score from 0 to 10. Our methodology assigns each essay to a particular category. If an essay is categorized by my model as being in Bucket 6 , then it receives a score of 5 . Models like BERT, RoBERTa, ALBERT, DistilBERT, and XLM-RoBERT 4 4 4 we used base models for our experiment were used to teach augmented essays how to recognize multiple labels.
We approached this issue in the same manner as sentiment analysis, which utilizes classification algorithms and yields extremely positive results. We have discovered that using this data augmentation training method contributes to an improvement in accuracy as referenced in Table V . From these results, it is quite evident that BERT and RoBERTa outperform other models, although by a small margin. The analysis of these findings demonstrates that utilizing Transformer-based models is considerably superior than using LSTMs.
When used on top of huge pre-trained classification models, our data augmentation strategies significantly enhance the performance of automated essay grading. The accuracy of all those pre-trained models increases after applying our augmentation technique. We believe this performance is because after mixing a summary of the topic with each essay, it encourages the internal representation of each essay to align with the topic, so that when we test it on a essay with a different topic after fine tuning, it checks for the alignment between the topic and the essay as a result of training and fine-tuning and grades it accordingly.
VI Conclusion and Future work
In this paper, we automated essay grading using transformer based models and an augmentation approach. The conclusion are as follows:
Pre-trained transformer-based models BERT, RoBERTa, ALBERT, DistilBERT, and XLM-RoBERTa are very proficient at Automated Essay Scoring.
Data augmentation approaches might further enhance its performance for analyzing lengthier resources such as essays to attain accurate essay scores.
In the future, we’ll come up with a better way to include elements that are relevant to the topic instead of just a summary, so that training with this data will lead to a more accurate model for automatically grading essays.
- [1] Ajay HB, Tillett PI, Page EB (1973) Analysis of essays by computer (AEC-II) (No. 8-0102). Washington, DC: U.S. Department of Health, Education, and Welfare, Office of Education, National Center for Educational Research and Development.
- [2] Shermis MD, Mzumara HR, Olson J, Harrington S (2001) On-line grading of student essays: PEG goes on the World Wide Web. Assess Eval High Educ 26(3):247–259.
- [3] Foltz PW, Laham D, Landauer TK (1999) The Intelligent Essay Assessor: Applications to Educational Technology. Interactive Multimedia Electronic Journal of Computer-Enhanced Learning, 1, 2, http://imej.wfu.edu/articles/1999/2/04/index.asp.
- [4] Rudner, L. M., Liang, T. (2002). Automated essay scoring using Bayes’ theorem. The Journal of Technology, Learning and Assessment, 1(2).
- [5] Dong F, Zhang Y, Yang J (2017) Attention-based recurrent convolutional neural network for automatic essay scoring. In: Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017) p 153–162.
- [6] Blood, I. (2011). Automated essay scoring: a literature review. Studies in Applied Linguistics and TESOL, 11(2).
- [7] Burrows S, Gurevych I, Stein B (2015) The eras and trends of automatic short answer grading. Int J Artif Intell Educ 25:60–117. https://doi.org/10.1007/s40593-014-0026-8.
- [8] Ke Z, Ng V (2019) “Automated essay scoring: a survey of the state of the art.” IJCAI
- [9] Hussein, M. A., Hassan, H., Nassef, M. (2019). Automated language essay scoring systems: A literature review. PeerJ Computer Science, 5, e208.
- [10] Klebanov, B. B., Madnani, N. (2020, July). Automated evaluation of writing–50 years and counting. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 7796–7810).
- [11] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. ”Attention is all you need.” Advances in neural information processing systems 30 (2017).
- [12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- [13] Liu, Yinhan, Ott, Myle, Goyal, Naman, Du, Jingfei, Joshi, Mandar, Chen, Danqi, Levy, Omer, Lewis, Mike, Zettlemoyer, Luke and Stoyanov, Veselin RoBERTa: A Robustly Optimized BERT Pretraining Approach. (2019). , cite arxiv:1907.11692.
- [14] Lan, Zhenzhong, Chen, Mingda, Goodman, Sebastian, Gimpel, Kevin, Sharma, Piyush and Soricut, Radu. ”ALBERT: A Lite BERT for Self-supervised Learning of Language Representations..” Paper presented at the meeting of the ICLR, 2020.
- [15] Sanh, Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. ”DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019).
- [16] Conneau, Alexis, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. ”Unsupervised cross-lingual representation learning at scale.” arXiv preprint arXiv:1911.02116 (2019).
- [17] Wolf, Thomas, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac et al. ”Huggingface’s transformers: State-of-the-art natural language processing.” arXiv preprint arXiv:1910.03771 (2019)
- [18] Lewis, Mike, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. ”Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.” arXiv preprint arXiv:1910.13461 (2019).
- [19] Ramesh, Dadi, and Suresh Kumar Sanampudi. ”An automated essay scoring systems: a systematic literature review.” Artificial Intelligence Review (2021): 1-33.
- [20] Elijah Mayfield and Alan W Black. 2020. Should You Fine-Tune BERT for Automated Essay Scoring?. In Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 151–162, Seattle, WA, USA → Online. Association for Computational Linguistics.
- [21] Ludwig, Sabrina, et al. ”Automated essay scoring using transformer models.” Psych 3.4 (2021): 897-915.
- [22] Ormerod, Christopher M., Akanksha Malhotra, and Amir Jafari. ”Automated essay scoring using efficient transformer-based language models.” arXiv preprint arXiv:2102.13136 (2021).
- [23] Park, Yo-Han, et al. ”EssayGAN: Essay Data Augmentation Based on Generative Adversarial Networks for Automated Essay Scoring.” Applied Sciences 12.12 (2022): 5803.
- [24] Jong, You-Jin, Yong-Jin Kim, and Ok-Chol Ri. ”Improving Performance of Automated Essay Scoring by using back-translation essays and adjusted scores.” Mathematical Problems in Engineering 2022 (2022).
- [25] Wang, Yongjie, et al. ”On the Use of BERT for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation.” arXiv preprint arXiv:2205.03835 (2022).
- [26] Sethi, Angad, and Kavinder Singh. ”Natural Language Processing based Automated Essay Scoring with Parameter-Efficient Transformer Approach.” 2022 6th International Conference on Computing Methodologies and Communication (ICCMC). IEEE, 2022.
An optimized LSTM-based augmented Language Model (FLSTM-ALM) using Fox algorithm for Automatic Essay Scoring Prediction
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

Automated essay scoring using efficient transformer-based language models

2021, ArXiv
Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written. Large pretrained transformer-based language models have dominated the current stateof-the-art in many NLP tasks, however, the computational requirements of these models make them expensive to deploy in practice. The goal of this paper is to challenge the paradigm in NLP that bigger is better when it comes to AES. To do this, we evaluate the performance of several fine-tuned pretrained NLP models with a modest number of parameters on an AES dataset. By ensembling our models, we achieve excellent results with fewer parameters than most pretrained transformer-based models.
RELATED TOPICS
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
COMMENTS
Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written. Large pretrained transformer-based language models have dominated the current state-of-the-art in many NLP tasks ...
Abstract and Figures. Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES ...
Automated essay scoring (AES) is gaining increasing attention in the education sector as it significantly reduces the burden of manual scoring and allows ad hoc feedback for learners. Natural language processing based on machine learning has been shown to be particularly suitable for text classification and AES. While many machine-learning approaches for AES still rely on a bag of words (BOW ...
This paper evaluates the performance of several fine-tuned pretrained NLP models with a modest number of parameters on an AES dataset and achieves excellent results with fewer parameters than most pretrained transformer-based models. Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP).
TABLE 1. A summary of the Automated Student Assessment Prize Automated Essay Scoring data-set. - "Automated essay scoring using efficient transformer-based language models"
The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written. Large pretrained transformer-based language models have dominated the current state-of-the-art in many NLP tasks, however, the computational requirements of these models make them expensive to deploy ...
Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written. Large pretrained transformer-based language models have dominated ...
the efficiency of the transformer-based models will further increase in the future and, additionally , that much smaller models with adequate language models for AES will be developed.
We study the effects of data size and quality on the performance on Automated Essay Scoring (AES) engines that are designed in accordance with three different paradigms; A frequency and hand-crafted feature-based model, a recurrent neural network model, and a pretrained transformer-based language model that is fine-tuned for classification.
Automated Essay Scoring Using Transformer Models. Automated essay scoring (AES) is gaining increasing attention in the education sector as it significantly reduces the burden of manual scoring and allows ad hoc feedback for learners. Natural language processing based on machine learning has been shown to be particularly suitable for text ...
2. Methodological Background for Automated Essay Scoring and NLP based on Neural Networks 2.1 Traditional Approaches Automated essay scoring has a long history. In the early 1960s, the Project Essay Grade system (PEG), as one of the first automated essay scoring systems was developed by Page [5 .7]. In the first attempts, four raters
The best language models are currently all based on transformer architectures [14]. More details on transformers are given in the corresponding chapter below. 2.2. Traditional Approaches Automated essay scoring has a long history. In the early 1960s, the Project Essay Grade system (PEG), one of the first automated essay scoring systems, was ...
Transfer learning is proving quite useful in Natural Language Processing. One of the most important problem in Natural Language Processing is Automated essay scoring, which remains partially unsolved especially when we are dealing with single language model capable to evaluate essays of multiple topics. In this work we examine the effectiveness of transformer models like BERT, RoBERTa, etc ...
Automated Essay Scoring (AES) is a well-studied problem in Natural Language Processing applied in education. Solutions vary from handcrafted linguistic features to large Transformer-based models, implying a significant effort in feature extraction and model implementation. We introduce a novel Automated Machine Learning (AutoML) pipeline integrated into the ReaderBench platform designed to ...
Existing automated scoring models implement layers of traditional recurrent neural networks to achieve reasonable performance. However, the models provide limited performance due to the limited capacity to encode long-term dependencies. The paper proposed a novel architecture incorporating pioneering language models of the natural language processing community. We leverage pre-trained language ...
H-AES: Towards Automated Essay Scoring for Hindi. This study reproduces and compares state-of-the-art methods for AES in the Hindi domain using classical feature-based Machine Learning and advanced end-to-end models, including LSTM Networks and Fine-Tuned Transformer Architecture and derives results comparable to those in the English language ...
TABLE 2. A summary of the memory and approximations of the computational requirements of the models we use in the study when comparing to BERT. These are estimates based on single epoch times using a fixed batch-size in training and inference. - "Automated essay scoring using efficient transformer-based language models"
Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written.
Ludwig (2021), Ormerod (2021) and Sethi (2022) examined the transformer based models on automated essay scoring, these ... Akanksha Malhotra, and Amir Jafari. "Automated essay scoring using efficient transformer-based language models." arXiv preprint arXiv:2102.13136 (2021). ... and Kavinder Singh. "Natural Language Processing based ...
The computer-based Automated Essay Scoring (AES) system automatically marks or scores student replies by considering relevant criteria. The methodology, which systematically categorizes writing quality, can increase operational effectiveness in academic and major commercial institutions. To study the projected score, AES relies on extracting numerous aspects from the student's response ...
AAAI. 2023. TLDR. This study reproduces and compares state-of-the-art methods for AES in the Hindi domain using classical feature-based Machine Learning and advanced end-to-end models, including LSTM Networks and Fine-Tuned Transformer Architecture and derives results comparable to those in the English language domain. 2.
Automated essay scoring using efficient transformer-based language models Christopher M. Ormerod, Akanksha Malhotra, and Amir Jafari arXiv:2102.13136v1 [cs.CL] 25 Feb 2021 A BSTRACT. Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP).