- Technical Support
- Find My Rep

You are here
How to get published.
You believe your research will make a contribution to your field, and you’re ready to share it with your peers far and wide, but how do you go about getting it published, and what exactly does that involve?
If this is you, this page is a great place to start. Here you’ll find guidance to taking those first steps towards publication with confidence. From what to consider when choosing a journal, to how to submit an article and what happens next.
Getting started
Choosing the right journal for you.
Submitting your article to a Sage journal
Promoting your article
Related resources you may find useful.

How to Get Your Journal Article Published guide
Our handy guide is a quick overview covering the publishing process from preparing your article and choosing a journal, to publication (5 minute read).
View the How to Get Your Journal Article Published guide

How to Get Published webinars
Free 1 hour monthly How to Get Published webinars cover topics including writing an article, navigating the peer review process, and what exactly it means when you hear “open access.” Join fellow researchers and expert speakers live, or watch our library of recordings on a variety of topics.
Browse our webinars

Sage Perspectives blog
Looking for tips on how to make sure your article goes smoothly through the peer review process, or how to write the right title for your article?
Read our blog

Sage Campus courses
Want something a bit more in-depth? Sage Campus courses are short and interactive (around 2 hours each) and cover a range of skills, including how to get published. Your library may already subscribe to the modules, or you may want to recommend that they do. Meanwhile, you can utilize the free modules.
Explore Sage Campus

Each journal has its own Aims & Scope, so the acceptance of articles is not just about quality, but also about being a good fit. Does your work reflect the scope of the Journal? Is Open Access important to you, and does the Journal have an Open Access model available? What is the readership of the Journal, and is that readership the right audience for your work? Researching the best match for your manuscript will significantly improve your chances of being accepted.
Watch our 2 minute video

If you already know in which Sage journal you’d like to publish your work, search for it and check the manuscript submission guidelines to make sure it is a good match. Or use the Sage Journal Recommender to tell us your article title and subjects and see which journals are a potential home for your manuscript. Be prepared to adjust your manuscript to match the scope and style of the desired journal.
Find journals with the Sage Journal Recommender or browse all Sage journals

Professional presentation of your work includes a precise and clear writing style, avoiding accidental plagiarism, and formatting your article to meet the criteria of your chosen journal. All of these take time and may not be skills inherent to your field of research. Sage Author Services can help you to prepare your manuscript to comply with these and other related standards, which could significantly improve your chance of acceptance.
Visit Sage Author Services
Submitting your article to a Sage journal
You’ve identified the right journal; now you need to make sure your manuscript is the perfect fit. Following the author guidelines can be the difference between possible acceptance and rejection, so it’s definitely worth following the required guidelines. We’ve a selection of resources and guides to help:
Watch How to Get Published: Submitting Your Paper (2 minute video)
Read our Article Submission infographic , a quick reminder of essentials
Here you’ll find chapter and verse on all aspects of our Manuscript Submission Guidelines
Ready to submit? Our online Submission Checklist will help you do a final check before sending your article to us.
Each journal retains editorial independence, which means their Guidelines will vary, so do go to the home page of your chosen journal to check anything you should be aware of. You can submit your article there too.

The academic world is crowded, how can you make your article stand out? If you are active on social media platforms, telling your followers about your article is one of the simplest and most effective things you can do.

Between us, we can improve the chances of your article being found, read, downloaded and cited – of your article and you making an impact. Our tips and guidance will show you how to promote your article alongside building your academic profile.
Read our tips on how to maximize your impact

- How to Get Published for Librarians
- How to Do Research and Get Published Webinar Series
- Manuscript Submission Guidelines
- Sage Author Services
- Your Paper and Peer Review
- Plain Language Summaries
- Advance: a Sage preprints community
- The Sage Production Process
- Help Readers Find Your Article
- Promote Your Article
- Research Data Sharing Policies
- Career and Networking Resources
- Open Access Publishing Options
- Top Reasons to Publish with Sage
- Open Access Introduction for Authors
- Journal Editor Gateway
- Journal Reviewer Gateway
- Ethics & Responsibility
- Sage Editorial Policies
- Publication Ethics Policies
- Sage Chinese Author Gateway 中国作者资源
- Open Resources & Current Initiatives
- Discipline Hubs
How to publish your work in a peer-reviewed journal: A short guide
Affiliation.
- 1 Head of Clinical Governance, Icon Oncology; Emeritus Professor of Radiation Oncology, University of Cape Town, South Africa. [email protected].
- PMID: 32880339
- DOI: 10.7196/SAMJ.2020.v110i7.14679
The basis of a manuscript is the research question, which is reported within a standard publication structure. The 'Background' section clarifies the question. The 'Methods' section describes what was done in the study. The 'Results' section describes the data observed and the analysis of these data. The 'Discussion' section describes how findings of the study relate to current knowledge and the practical implications of the results, and suggests future studies. This structure differs from that of a thesis, the aims of which are broader than reporting on a specific research question.
- Peer Review, Research*
- Periodicals as Topic
- Publishing*
- Research Design
How to Publish a Research Article
- Submit your Research
- My Submissions
- Article Guidelines
- Article Guidelines (New Versions)
- Data Guidelines
- Article Processing Charges
- Finding Article Reviewers
- The Peer Review Process
- The Editorial Team’s Role
- Reviewer Criteria
- Dos and Don’ts for Suggesting Reviewers
- Hints and Tips for Finding Reviewers
- The work is original. The article (or substantial parts of it) must not have been published previously, or be under consideration or review by another journal. Articles previously posted on a preprint server, such as arXiv, SSRN, BioRxiv, MedRxiv can be submitted for publication in Open Research Europe.
- At least one author must have or previously had Horizon 2020 funding (for details, see our Publication criteria ).
- The reported study meets all applicable research and publication standards . We strongly recommend that you consult our editorial policies for more detail on reporting guidelines and ethical requirements.
- Where applicable, all methodological details and relevant data are made available to allow others to replicate the study, and that the article adheres to appropriate reporting guidelines and community standards. For more detail, please see our policies and Data preparation guidelines .
- All authors have understood Routledge Open Research’s policies for article publication and its author-led publishing model , which requires authors to actively suggest suitable peer reviewers for their article until at least 2 reviews have been received.
- Your article includes full author and affiliation information, and a conflict of interest statement.

- ORCID allows identification beyond names. Globally, names can be very common, they can change, they can be transliterated into other alphabets and so reliably linking researchers with their research and organizations can be difficult - this is solved through a unique ORCID iD.
- An ORCID iD also allows you to keep a constantly updated digital curriculum vitae. Individuals decide to register, which research activities to connect to their ID, which organizations to allow access, what information to make publicly available, what to share with trusted parties, and what to keep private. Individuals can control their profiles and can change these settings and permissions at any time.
- we collect and store authenticated ORCID iDs for authors and reviewers
- we publicly display the iDs with the iD icon for those authors and reviewers, linked to their ORCID account
- we connect to the user's ORCID record and update it with new published works

Stay Informed
Sign up for information about developments, publishing and publications from Routledge Open Research.
We'll keep you updated on any major new updates to Routledge Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here .
If you still need help with your Google account password, please click here .
You registered with F1000 via Facebook, so we cannot reset your password.
If you still need help with your Facebook account password, please click here .
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
How to Write a Peer Review

When you write a peer review for a manuscript, what should you include in your comments? What should you leave out? And how should the review be formatted?
This guide provides quick tips for writing and organizing your reviewer report.
Review Outline
Use an outline for your reviewer report so it’s easy for the editors and author to follow. This will also help you keep your comments organized.
Think about structuring your review like an inverted pyramid. Put the most important information at the top, followed by details and examples in the center, and any additional points at the very bottom.
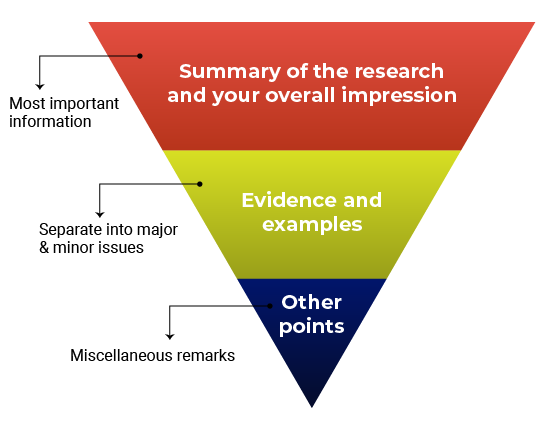
Here’s how your outline might look:
1. Summary of the research and your overall impression
In your own words, summarize what the manuscript claims to report. This shows the editor how you interpreted the manuscript and will highlight any major differences in perspective between you and the other reviewers. Give an overview of the manuscript’s strengths and weaknesses. Think about this as your “take-home” message for the editors. End this section with your recommended course of action.
2. Discussion of specific areas for improvement
It’s helpful to divide this section into two parts: one for major issues and one for minor issues. Within each section, you can talk about the biggest issues first or go systematically figure-by-figure or claim-by-claim. Number each item so that your points are easy to follow (this will also make it easier for the authors to respond to each point). Refer to specific lines, pages, sections, or figure and table numbers so the authors (and editors) know exactly what you’re talking about.
Major vs. minor issues
What’s the difference between a major and minor issue? Major issues should consist of the essential points the authors need to address before the manuscript can proceed. Make sure you focus on what is fundamental for the current study . In other words, it’s not helpful to recommend additional work that would be considered the “next step” in the study. Minor issues are still important but typically will not affect the overall conclusions of the manuscript. Here are some examples of what would might go in the “minor” category:
- Missing references (but depending on what is missing, this could also be a major issue)
- Technical clarifications (e.g., the authors should clarify how a reagent works)
- Data presentation (e.g., the authors should present p-values differently)
- Typos, spelling, grammar, and phrasing issues
3. Any other points
Confidential comments for the editors.
Some journals have a space for reviewers to enter confidential comments about the manuscript. Use this space to mention concerns about the submission that you’d want the editors to consider before sharing your feedback with the authors, such as concerns about ethical guidelines or language quality. Any serious issues should be raised directly and immediately with the journal as well.
This section is also where you will disclose any potentially competing interests, and mention whether you’re willing to look at a revised version of the manuscript.
Do not use this space to critique the manuscript, since comments entered here will not be passed along to the authors. If you’re not sure what should go in the confidential comments, read the reviewer instructions or check with the journal first before submitting your review. If you are reviewing for a journal that does not offer a space for confidential comments, consider writing to the editorial office directly with your concerns.
Get this outline in a template
Giving Feedback
Giving feedback is hard. Giving effective feedback can be even more challenging. Remember that your ultimate goal is to discuss what the authors would need to do in order to qualify for publication. The point is not to nitpick every piece of the manuscript. Your focus should be on providing constructive and critical feedback that the authors can use to improve their study.
If you’ve ever had your own work reviewed, you already know that it’s not always easy to receive feedback. Follow the golden rule: Write the type of review you’d want to receive if you were the author. Even if you decide not to identify yourself in the review, you should write comments that you would be comfortable signing your name to.
In your comments, use phrases like “ the authors’ discussion of X” instead of “ your discussion of X .” This will depersonalize the feedback and keep the focus on the manuscript instead of the authors.
General guidelines for effective feedback

- Justify your recommendation with concrete evidence and specific examples.
- Be specific so the authors know what they need to do to improve.
- Be thorough. This might be the only time you read the manuscript.
- Be professional and respectful. The authors will be reading these comments too.
- Remember to say what you liked about the manuscript!

Don’t
- Recommend additional experiments or unnecessary elements that are out of scope for the study or for the journal criteria.
- Tell the authors exactly how to revise their manuscript—you don’t need to do their work for them.
- Use the review to promote your own research or hypotheses.
- Focus on typos and grammar. If the manuscript needs significant editing for language and writing quality, just mention this in your comments.
- Submit your review without proofreading it and checking everything one more time.
Before and After: Sample Reviewer Comments
Keeping in mind the guidelines above, how do you put your thoughts into words? Here are some sample “before” and “after” reviewer comments
✗ Before
“The authors appear to have no idea what they are talking about. I don’t think they have read any of the literature on this topic.”
✓ After
“The study fails to address how the findings relate to previous research in this area. The authors should rewrite their Introduction and Discussion to reference the related literature, especially recently published work such as Darwin et al.”
“The writing is so bad, it is practically unreadable. I could barely bring myself to finish it.”
“While the study appears to be sound, the language is unclear, making it difficult to follow. I advise the authors work with a writing coach or copyeditor to improve the flow and readability of the text.”
“It’s obvious that this type of experiment should have been included. I have no idea why the authors didn’t use it. This is a big mistake.”
“The authors are off to a good start, however, this study requires additional experiments, particularly [type of experiment]. Alternatively, the authors should include more information that clarifies and justifies their choice of methods.”
Suggested Language for Tricky Situations
You might find yourself in a situation where you’re not sure how to explain the problem or provide feedback in a constructive and respectful way. Here is some suggested language for common issues you might experience.
What you think : The manuscript is fatally flawed. What you could say: “The study does not appear to be sound” or “the authors have missed something crucial”.
What you think : You don’t completely understand the manuscript. What you could say : “The authors should clarify the following sections to avoid confusion…”
What you think : The technical details don’t make sense. What you could say : “The technical details should be expanded and clarified to ensure that readers understand exactly what the researchers studied.”
What you think: The writing is terrible. What you could say : “The authors should revise the language to improve readability.”
What you think : The authors have over-interpreted the findings. What you could say : “The authors aim to demonstrate [XYZ], however, the data does not fully support this conclusion. Specifically…”
What does a good review look like?
Check out the peer review examples at F1000 Research to see how other reviewers write up their reports and give constructive feedback to authors.
Time to Submit the Review!
Be sure you turn in your report on time. Need an extension? Tell the journal so that they know what to expect. If you need a lot of extra time, the journal might need to contact other reviewers or notify the author about the delay.
Tip: Building a relationship with an editor
You’ll be more likely to be asked to review again if you provide high-quality feedback and if you turn in the review on time. Especially if it’s your first review for a journal, it’s important to show that you are reliable. Prove yourself once and you’ll get asked to review again!
- Getting started as a reviewer
- Responding to an invitation
- Reading a manuscript
- Writing a peer review
The contents of the Peer Review Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
The contents of the Writing Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
There’s a lot to consider when deciding where to submit your work. Learn how to choose a journal that will help your study reach its audience, while reflecting your values as a researcher…
- International edition
- Australia edition
- Europe edition

How to get published in an academic journal: top tips from editors
Journal editors share their advice on how to structure a paper, write a cover letter - and deal with awkward feedback from reviewers
- Overcoming writer’s block: three tips
- How to write for an academic journal
Writing for academic journals is highly competitive. Even if you overcome the first hurdle and generate a valuable idea or piece of research - how do you then sum it up in a way that will capture the interest of reviewers?
There’s no simple formula for getting published - editors’ expectations can vary both between and within subject areas. But there are some challenges that will confront all academic writers regardless of their discipline. How should you respond to reviewer feedback? Is there a correct way to structure a paper? And should you always bother revising and resubmitting? We asked journal editors from a range of backgrounds for their tips on getting published.
The writing stage
1) Focus on a story that progresses logically, rather than chronologically
Take some time before even writing your paper to think about the logic of the presentation. When writing, focus on a story that progresses logically, rather than the chronological order of the experiments that you did. Deborah Sweet, editor of Cell Stem Cell and publishing director at Cell Press
2) Don’t try to write and edit at the same time
Open a file on the PC and put in all your headings and sub-headings and then fill in under any of the headings where you have the ideas to do so. If you reach your daily target (mine is 500 words) put any other ideas down as bullet points and stop writing; then use those bullet points to make a start the next day.
If you are writing and can’t think of the right word (eg for elephant) don’t worry - write (big animal long nose) and move on - come back later and get the correct term. Write don’t edit; otherwise you lose flow. Roger Watson, editor-in-chief, Journal of Advanced Nursing
3) Don’t bury your argument like a needle in a haystack
If someone asked you on the bus to quickly explain your paper, could you do so in clear, everyday language? This clear argument should appear in your abstract and in the very first paragraph (even the first line) of your paper. Don’t make us hunt for your argument as for a needle in a haystack. If it is hidden on page seven that will just make us annoyed. Oh, and make sure your argument runs all the way through the different sections of the paper and ties together the theory and empirical material. Fiona Macaulay, editorial board, Journal of Latin American Studies
4) Ask a colleague to check your work
One of the problems that journal editors face is badly written papers. It might be that the writer’s first language isn’t English and they haven’t gone the extra mile to get it proofread. It can be very hard to work out what is going on in an article if the language and syntax are poor. Brian Lucey, editor, International Review of Financial Analysis
5) Get published by writing a review or a response
Writing reviews is a good way to get published - especially for people who are in the early stages of their career. It’s a chance to practice at writing a piece for publication, and get a free copy of a book that you want. We publish more reviews than papers so we’re constantly looking for reviewers.
Some journals, including ours, publish replies to papers that have been published in the same journal. Editors quite like to publish replies to previous papers because it stimulates discussion. Yujin Nagasawa, c o-editor and review editor of the European Journal for Philosophy of Religion , philosophy of religion editor of Philosophy Compass
6) Don’t forget about international readers
We get people who write from America who assume everyone knows the American system - and the same happens with UK writers. Because we’re an international journal, we need writers to include that international context. Hugh McLaughlin, editor in chief, Social Work Education - the International Journal
7) Don’t try to cram your PhD into a 6,000 word paper
Sometimes people want to throw everything in at once and hit too many objectives. We get people who try to tell us their whole PhD in 6,000 words and it just doesn’t work. More experienced writers will write two or three papers from one project, using a specific aspect of their research as a hook. Hugh McLaughlin, editor in chief, Social Work Education - the International Journal
Submitting your work
8) Pick the right journal: it’s a bad sign if you don’t recognise any of the editorial board
Check that your article is within the scope of the journal that you are submitting to. This seems so obvious but it’s surprising how many articles are submitted to journals that are completely inappropriate. It is a bad sign if you do not recognise the names of any members of the editorial board. Ideally look through a number of recent issues to ensure that it is publishing articles on the same topic and that are of similar quality and impact. Ian Russell, editorial director for science at Oxford University Press
9) Always follow the correct submissions procedures
Often authors don’t spend the 10 minutes it takes to read the instructions to authors which wastes enormous quantities of time for both the author and the editor and stretches the process when it does not need to Tangali Sudarshan, editor, Surface Engineering
10) Don’t repeat your abstract in the cover letter We look to the cover letter for an indication from you about what you think is most interesting and significant about the paper, and why you think it is a good fit for the journal. There is no need to repeat the abstract or go through the content of the paper in detail – we will read the paper itself to find out what it says. The cover letter is a place for a bigger picture outline, plus any other information that you would like us to have. Deborah Sweet, editor of Cell Stem Cell and publishing director at Cell Press
11) A common reason for rejections is lack of context
Make sure that it is clear where your research sits within the wider scholarly landscape, and which gaps in knowledge it’s addressing. A common reason for articles being rejected after peer review is this lack of context or lack of clarity about why the research is important. Jane Winters, executive editor of the Institute of Historical Research’s journal, Historical Research and associate editor of Frontiers in Digital Humanities: Digital History
12) Don’t over-state your methodology
Ethnography seems to be the trendy method of the moment, so lots of articles submitted claim to be based on it. However, closer inspection reveals quite limited and standard interview data. A couple of interviews in a café do not constitute ethnography. Be clear - early on - about the nature and scope of your data collection. The same goes for the use of theory. If a theoretical insight is useful to your analysis, use it consistently throughout your argument and text. Fiona Macaulay, editorial board, Journal of Latin American Studies
Dealing with feedback
13) Respond directly (and calmly) to reviewer comments
When resubmitting a paper following revisions, include a detailed document summarising all the changes suggested by the reviewers, and how you have changed your manuscript in light of them. Stick to the facts, and don’t rant. Don’t respond to reviewer feedback as soon as you get it. Read it, think about it for several days, discuss it with others, and then draft a response. Helen Ball, editorial board, Journal of Human Lactation
14) Revise and resubmit: don’t give up after getting through all the major hurdles
You’d be surprised how many authors who receive the standard “revise and resubmit” letter never actually do so. But it is worth doing - some authors who get asked to do major revisions persevere and end up getting their work published, yet others, who had far less to do, never resubmit. It seems silly to get through the major hurdles of writing the article, getting it past the editors and back from peer review only to then give up. Fiona Macaulay, editorial board, Journal of Latin American Studies
15) It is acceptable to challenge reviewers, with good justification
It is acceptable to decline a reviewer’s suggestion to change a component of your article if you have a good justification, or can (politely) argue why the reviewer is wrong. A rational explanation will be accepted by editors, especially if it is clear you have considered all the feedback received and accepted some of it. Helen Ball, editorial board of Journal of Human Lactation
16) Think about how quickly you want to see your paper published
Some journals rank more highly than others and so your risk of rejection is going to be greater. People need to think about whether or not they need to see their work published quickly - because certain journals will take longer. Some journals, like ours, also do advance access so once the article is accepted it appears on the journal website. This is important if you’re preparing for a job interview and need to show that you are publishable. Hugh McLaughlin, editor in chief, Social Work Education - the International Journal
17) Remember: when you read published papers you only see the finished article
Publishing in top journals is a challenge for everyone, but it may seem easier for other people. When you read published papers you see the finished article, not the first draft, nor the first revise and resubmit, nor any of the intermediate versions – and you never see the failures. Philip Powell, managing editor of the Information Systems Journal
Enter the Guardian university awards 2015 and join the higher education network for more comment, analysis and job opportunities, direct to your inbox. Follow us on Twitter @gdnhighered .
- Universities
- University careers
- Higher education
Comments (…)
Most viewed.
- Expert Journal of Finance
- Expert Journal of Economics
- Expert Journal of Marketing
- Expert Journal of Business and Management
- Send Your Article
- Google Plus
How to Publish Your Article in a Peer-Reviewed Journal: Survival Guide
The Pee Review process, or the refereeing process, is a complex and necessary step in the publishing process. However, the main purpose of this thorough process is to bring valuable academic journal articles in the world that other Researchers and Authors can use, access, share, and expand upon them.
A thorough and complex peer review process is a necessary step because it promotes a high quality journal publication process that brings valuable academic articles into the world. Moreover, Authors benefit from new perspectives about their work, using the insights from experienced Editors and Reviewers.
For any academic journal, the main objectives related to the peer review process should be to help Authors improve their work and to publish valuable high quality research papers that expand on a particular field study.
Peer Review Criteria of Editors and Reviewers
The most used type of scholarly journal article evaluation, is the double blind peer review which represents a very holistic and meticulous evaluation framework. This peer review starts with the Editor’s review, and, if a paper obtains grades that classify it for the next evaluation stage, then the manuscript will be examined by one or more expert Reviewers on a particular subject.
In the following sections, we examine the main differences between the two reviewing processes, and the criteria that are usually evaluated in the double blind peer review process.
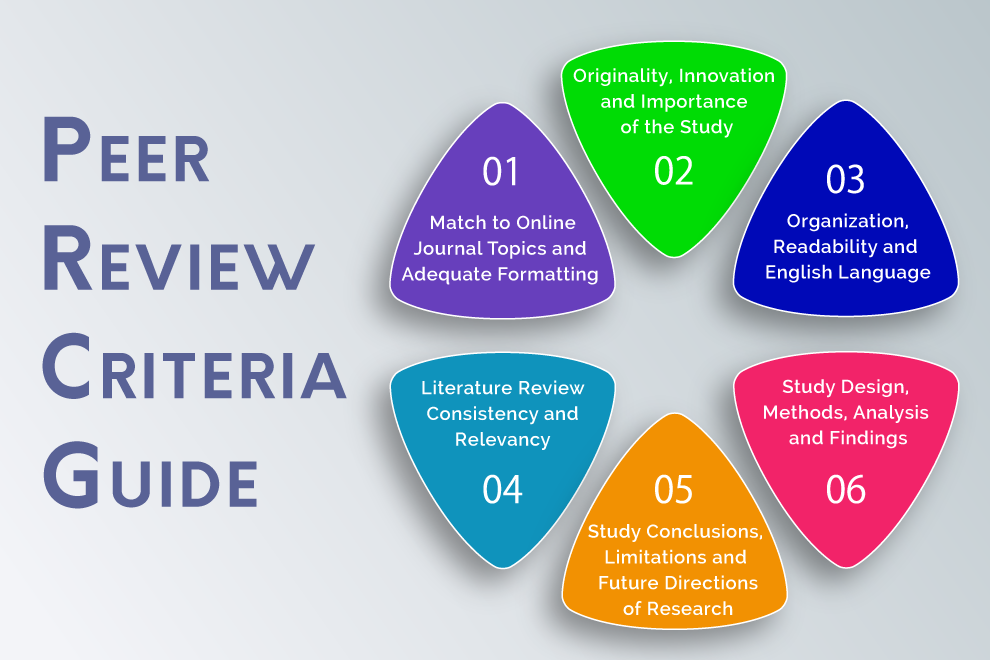
What Are Editors Evaluating in a Peer Review Process?
Every academic journal has a review form that Editors use as an appraisal for each received scholarly article. Editors grade and evaluate aspects, such as:
- Match to academic journal topics,
- Originality & plagiarism (every academic article has to undergo a plagiarism analysis using different software),
- Adequate formatting of the scholarly journal article in accordance with Author Guidelines,
- English language comprehension,
- Organization and structure,
- Readability,
- Relevancy of cited references,
- Quality and relevancy of figures and tables
Additionally, Editors can provide specific, constructive, and actionable suggestions for making the article a better fit for publishing in a particular academic journal.
What Are Reviewers Assessing in a Peer Review Process?
Like the Editors, expert Reviewers usually have a form they have to fill in about the academic article they will examine, and again there are various aspects that need to be addressed. Reviewers grade and assess criteria, such as:
- Literature review consistency,
- Contribution to existing literature review,
- English language and understanding,
- Readability and/or organization,
- Innovation of the ideas presented in the academic article,
- Study design, analysis, and results,
- Importance of the research paper,
- Clear purpose of the article,
- Study Contribution, Limitations and Future Research Directions
- Construction and/or Structure (in terms of title, abstract, sections of the scholarly journal article, etc.)
If applicable, Reviewers may further develop any of the peer review criteria, or provide extra observations on how to improve the overall research article.
Efficient Peer Review Process
Especially for open access publications , Authors expect a detailed and comprehensive assessment of their work, but they also value efficiency for their peer review process. Efficiency in the evaluation process is characterized by the number of days between article submission and final response of the peer review. The response of the evaluation consists of 4 options: Accepted without any reviews, Accepted with minor changes, Accepted with major changes, Rejected.
At Expert Journals, we strive to offer our Authors who choose our scholarly journals for article publication a rigorous and efficient peer review. For our four open access academic journals, the average number of days from manuscript submission to article acceptance is 22.45 days , thus benefiting of rapid journal publication .
Our main objectives related to the rigorous double peer review process are to help Authors improve their work, using insights from experienced Editors and Reviewers, and to publish valuable article that expand on a particular field study.
You may also like
Related policies and links, responsibilities of the publisher in the relationship with journal editors, general duties of publisher.

- SpringerLink shop
How to review an article - Overview
Despite the importance of peer review, the process of peer reviewing is rarely taught in universities. Compared with conducting research, teaching, and writing your own manuscripts, reviewing someone else’s work may seem relatively easy. In fact, reviewing is a special skill that takes time and effort to develop.
When peer reviewing, it is helpful to think from the point of view of three different groups of people:
- Authors . Try to review the manuscript as you would like others to review your work. When you point out problems in a manuscript, do so in a way that will help the authors to improve the manuscript. Assume that the authors are doing their best to produce an excellent manuscript but need objective outsiders to help identify problems in their methods, analysis, and presentation. Even if you recommend to the editor that the manuscript be rejected, your suggested revisions could help the authors prepare the manuscript for submission to a different journal.
- Journal editors . Comment on the importance and novelty of the study. Editors want to publish high-quality papers that will be cited. In choosing such papers, editors need expert help to determine if a manuscript’s research and analysis are sound, and if it makes an important contribution to the field. Peer reviewers help editors by improving the quality of manuscripts before they are published in the editor’s journal.
- Readers . Identify areas that need clarification to make sure other readers can easily understand the manuscript. As a reviewer, you can also save readers’ time and frustration by helping to keep unimportant or error filled research out of the published literature.
Writing a thorough, thoughtful review usually takes several hours or more. But by taking the time to be a good reviewer, you will be providing a service to the scientific community.
--- Commentary ---
Original URL: http://www.springer.com/authors/journal+authors/peer-review-academy?SGWID=0-1741413-12-959504-0
Picture Remarks:
Sebastian's remark: removed bulletpoints in front of the numbers!
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
Research Roundup: How the Pandemic Changed Management
- Mark C. Bolino,
- Jacob M. Whitney,
- Sarah E. Henry

Lessons from 69 articles published in top management and applied psychology journals.
Researchers recently reviewed 69 articles focused on the management implications of the Covid-19 pandemic that were published between March 2020 and July 2023 in top journals in management and applied psychology. The review highlights the numerous ways in which employees, teams, leaders, organizations, and societies were impacted and offers lessons for managing through future pandemics or other events of mass disruption.
The recent pandemic disrupted life as we know it, including for employees and organizations around the world. To understand such changes, we recently reviewed 69 articles focused on the management implications of the Covid-19 pandemic. These papers were published between March 2020 and July 2023 in top journals in management and applied psychology.
- Mark C. Bolino is the David L. Boren Professor and the Michael F. Price Chair in International Business at the University of Oklahoma’s Price College of Business. His research focuses on understanding how an organization can inspire its employees to go the extra mile without compromising their personal well-being.
- JW Jacob M. Whitney is a doctoral candidate in management at the University of Oklahoma’s Price College of Business and an incoming assistant professor at Kennesaw State University. His research interests include leadership, teams, and organizational citizenship behavior.
- SH Sarah E. Henry is a doctoral candidate in management at the University of Oklahoma’s Price College of Business and an incoming assistant professor at the University of South Florida. Her research interests include organizational citizenship behaviors, workplace interpersonal dynamics, and international management.
Partner Center
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 26 March 2024
Predicting and improving complex beer flavor through machine learning
- Michiel Schreurs ORCID: orcid.org/0000-0002-9449-5619 1 , 2 , 3 na1 ,
- Supinya Piampongsant 1 , 2 , 3 na1 ,
- Miguel Roncoroni ORCID: orcid.org/0000-0001-7461-1427 1 , 2 , 3 na1 ,
- Lloyd Cool ORCID: orcid.org/0000-0001-9936-3124 1 , 2 , 3 , 4 ,
- Beatriz Herrera-Malaver ORCID: orcid.org/0000-0002-5096-9974 1 , 2 , 3 ,
- Christophe Vanderaa ORCID: orcid.org/0000-0001-7443-5427 4 ,
- Florian A. Theßeling 1 , 2 , 3 ,
- Łukasz Kreft ORCID: orcid.org/0000-0001-7620-4657 5 ,
- Alexander Botzki ORCID: orcid.org/0000-0001-6691-4233 5 ,
- Philippe Malcorps 6 ,
- Luk Daenen 6 ,
- Tom Wenseleers ORCID: orcid.org/0000-0002-1434-861X 4 &
- Kevin J. Verstrepen ORCID: orcid.org/0000-0002-3077-6219 1 , 2 , 3
Nature Communications volume 15 , Article number: 2368 ( 2024 ) Cite this article
36k Accesses
741 Altmetric
Metrics details
- Chemical engineering
- Gas chromatography
- Machine learning
- Metabolomics
- Taste receptors
The perception and appreciation of food flavor depends on many interacting chemical compounds and external factors, and therefore proves challenging to understand and predict. Here, we combine extensive chemical and sensory analyses of 250 different beers to train machine learning models that allow predicting flavor and consumer appreciation. For each beer, we measure over 200 chemical properties, perform quantitative descriptive sensory analysis with a trained tasting panel and map data from over 180,000 consumer reviews to train 10 different machine learning models. The best-performing algorithm, Gradient Boosting, yields models that significantly outperform predictions based on conventional statistics and accurately predict complex food features and consumer appreciation from chemical profiles. Model dissection allows identifying specific and unexpected compounds as drivers of beer flavor and appreciation. Adding these compounds results in variants of commercial alcoholic and non-alcoholic beers with improved consumer appreciation. Together, our study reveals how big data and machine learning uncover complex links between food chemistry, flavor and consumer perception, and lays the foundation to develop novel, tailored foods with superior flavors.
Similar content being viewed by others

BitterSweet: Building machine learning models for predicting the bitter and sweet taste of small molecules
Rudraksh Tuwani, Somin Wadhwa & Ganesh Bagler

Sensory lexicon and aroma volatiles analysis of brewing malt
Xiaoxia Su, Miao Yu, … Tianyi Du

Predicting odor from molecular structure: a multi-label classification approach
Kushagra Saini & Venkatnarayan Ramanathan
Introduction
Predicting and understanding food perception and appreciation is one of the major challenges in food science. Accurate modeling of food flavor and appreciation could yield important opportunities for both producers and consumers, including quality control, product fingerprinting, counterfeit detection, spoilage detection, and the development of new products and product combinations (food pairing) 1 , 2 , 3 , 4 , 5 , 6 . Accurate models for flavor and consumer appreciation would contribute greatly to our scientific understanding of how humans perceive and appreciate flavor. Moreover, accurate predictive models would also facilitate and standardize existing food assessment methods and could supplement or replace assessments by trained and consumer tasting panels, which are variable, expensive and time-consuming 7 , 8 , 9 . Lastly, apart from providing objective, quantitative, accurate and contextual information that can help producers, models can also guide consumers in understanding their personal preferences 10 .
Despite the myriad of applications, predicting food flavor and appreciation from its chemical properties remains a largely elusive goal in sensory science, especially for complex food and beverages 11 , 12 . A key obstacle is the immense number of flavor-active chemicals underlying food flavor. Flavor compounds can vary widely in chemical structure and concentration, making them technically challenging and labor-intensive to quantify, even in the face of innovations in metabolomics, such as non-targeted metabolic fingerprinting 13 , 14 . Moreover, sensory analysis is perhaps even more complicated. Flavor perception is highly complex, resulting from hundreds of different molecules interacting at the physiochemical and sensorial level. Sensory perception is often non-linear, characterized by complex and concentration-dependent synergistic and antagonistic effects 15 , 16 , 17 , 18 , 19 , 20 , 21 that are further convoluted by the genetics, environment, culture and psychology of consumers 22 , 23 , 24 . Perceived flavor is therefore difficult to measure, with problems of sensitivity, accuracy, and reproducibility that can only be resolved by gathering sufficiently large datasets 25 . Trained tasting panels are considered the prime source of quality sensory data, but require meticulous training, are low throughput and high cost. Public databases containing consumer reviews of food products could provide a valuable alternative, especially for studying appreciation scores, which do not require formal training 25 . Public databases offer the advantage of amassing large amounts of data, increasing the statistical power to identify potential drivers of appreciation. However, public datasets suffer from biases, including a bias in the volunteers that contribute to the database, as well as confounding factors such as price, cult status and psychological conformity towards previous ratings of the product.
Classical multivariate statistics and machine learning methods have been used to predict flavor of specific compounds by, for example, linking structural properties of a compound to its potential biological activities or linking concentrations of specific compounds to sensory profiles 1 , 26 . Importantly, most previous studies focused on predicting organoleptic properties of single compounds (often based on their chemical structure) 27 , 28 , 29 , 30 , 31 , 32 , 33 , thus ignoring the fact that these compounds are present in a complex matrix in food or beverages and excluding complex interactions between compounds. Moreover, the classical statistics commonly used in sensory science 34 , 35 , 36 , 37 , 38 , 39 require a large sample size and sufficient variance amongst predictors to create accurate models. They are not fit for studying an extensive set of hundreds of interacting flavor compounds, since they are sensitive to outliers, have a high tendency to overfit and are less suited for non-linear and discontinuous relationships 40 .
In this study, we combine extensive chemical analyses and sensory data of a set of different commercial beers with machine learning approaches to develop models that predict taste, smell, mouthfeel and appreciation from compound concentrations. Beer is particularly suited to model the relationship between chemistry, flavor and appreciation. First, beer is a complex product, consisting of thousands of flavor compounds that partake in complex sensory interactions 41 , 42 , 43 . This chemical diversity arises from the raw materials (malt, yeast, hops, water and spices) and biochemical conversions during the brewing process (kilning, mashing, boiling, fermentation, maturation and aging) 44 , 45 . Second, the advent of the internet saw beer consumers embrace online review platforms, such as RateBeer (ZX Ventures, Anheuser-Busch InBev SA/NV) and BeerAdvocate (Next Glass, inc.). In this way, the beer community provides massive data sets of beer flavor and appreciation scores, creating extraordinarily large sensory databases to complement the analyses of our professional sensory panel. Specifically, we characterize over 200 chemical properties of 250 commercial beers, spread across 22 beer styles, and link these to the descriptive sensory profiling data of a 16-person in-house trained tasting panel and data acquired from over 180,000 public consumer reviews. These unique and extensive datasets enable us to train a suite of machine learning models to predict flavor and appreciation from a beer’s chemical profile. Dissection of the best-performing models allows us to pinpoint specific compounds as potential drivers of beer flavor and appreciation. Follow-up experiments confirm the importance of these compounds and ultimately allow us to significantly improve the flavor and appreciation of selected commercial beers. Together, our study represents a significant step towards understanding complex flavors and reinforces the value of machine learning to develop and refine complex foods. In this way, it represents a stepping stone for further computer-aided food engineering applications 46 .
To generate a comprehensive dataset on beer flavor, we selected 250 commercial Belgian beers across 22 different beer styles (Supplementary Fig. S1 ). Beers with ≤ 4.2% alcohol by volume (ABV) were classified as non-alcoholic and low-alcoholic. Blonds and Tripels constitute a significant portion of the dataset (12.4% and 11.2%, respectively) reflecting their presence on the Belgian beer market and the heterogeneity of beers within these styles. By contrast, lager beers are less diverse and dominated by a handful of brands. Rare styles such as Brut or Faro make up only a small fraction of the dataset (2% and 1%, respectively) because fewer of these beers are produced and because they are dominated by distinct characteristics in terms of flavor and chemical composition.
Extensive analysis identifies relationships between chemical compounds in beer
For each beer, we measured 226 different chemical properties, including common brewing parameters such as alcohol content, iso-alpha acids, pH, sugar concentration 47 , and over 200 flavor compounds (Methods, Supplementary Table S1 ). A large portion (37.2%) are terpenoids arising from hopping, responsible for herbal and fruity flavors 16 , 48 . A second major category are yeast metabolites, such as esters and alcohols, that result in fruity and solvent notes 48 , 49 , 50 . Other measured compounds are primarily derived from malt, or other microbes such as non- Saccharomyces yeasts and bacteria (‘wild flora’). Compounds that arise from spices or staling are labeled under ‘Others’. Five attributes (caloric value, total acids and total ester, hop aroma and sulfur compounds) are calculated from multiple individually measured compounds.
As a first step in identifying relationships between chemical properties, we determined correlations between the concentrations of the compounds (Fig. 1 , upper panel, Supplementary Data 1 and 2 , and Supplementary Fig. S2 . For the sake of clarity, only a subset of the measured compounds is shown in Fig. 1 ). Compounds of the same origin typically show a positive correlation, while absence of correlation hints at parameters varying independently. For example, the hop aroma compounds citronellol, and alpha-terpineol show moderate correlations with each other (Spearman’s rho=0.39 and 0.57), but not with the bittering hop component iso-alpha acids (Spearman’s rho=0.16 and −0.07). This illustrates how brewers can independently modify hop aroma and bitterness by selecting hop varieties and dosage time. If hops are added early in the boiling phase, chemical conversions increase bitterness while aromas evaporate, conversely, late addition of hops preserves aroma but limits bitterness 51 . Similarly, hop-derived iso-alpha acids show a strong anti-correlation with lactic acid and acetic acid, likely reflecting growth inhibition of lactic acid and acetic acid bacteria, or the consequent use of fewer hops in sour beer styles, such as West Flanders ales and Fruit beers, that rely on these bacteria for their distinct flavors 52 . Finally, yeast-derived esters (ethyl acetate, ethyl decanoate, ethyl hexanoate, ethyl octanoate) and alcohols (ethanol, isoamyl alcohol, isobutanol, and glycerol), correlate with Spearman coefficients above 0.5, suggesting that these secondary metabolites are correlated with the yeast genetic background and/or fermentation parameters and may be difficult to influence individually, although the choice of yeast strain may offer some control 53 .

Spearman rank correlations are shown. Descriptors are grouped according to their origin (malt (blue), hops (green), yeast (red), wild flora (yellow), Others (black)), and sensory aspect (aroma, taste, palate, and overall appreciation). Please note that for the chemical compounds, for the sake of clarity, only a subset of the total number of measured compounds is shown, with an emphasis on the key compounds for each source. For more details, see the main text and Methods section. Chemical data can be found in Supplementary Data 1 , correlations between all chemical compounds are depicted in Supplementary Fig. S2 and correlation values can be found in Supplementary Data 2 . See Supplementary Data 4 for sensory panel assessments and Supplementary Data 5 for correlation values between all sensory descriptors.
Interestingly, different beer styles show distinct patterns for some flavor compounds (Supplementary Fig. S3 ). These observations agree with expectations for key beer styles, and serve as a control for our measurements. For instance, Stouts generally show high values for color (darker), while hoppy beers contain elevated levels of iso-alpha acids, compounds associated with bitter hop taste. Acetic and lactic acid are not prevalent in most beers, with notable exceptions such as Kriek, Lambic, Faro, West Flanders ales and Flanders Old Brown, which use acid-producing bacteria ( Lactobacillus and Pediococcus ) or unconventional yeast ( Brettanomyces ) 54 , 55 . Glycerol, ethanol and esters show similar distributions across all beer styles, reflecting their common origin as products of yeast metabolism during fermentation 45 , 53 . Finally, low/no-alcohol beers contain low concentrations of glycerol and esters. This is in line with the production process for most of the low/no-alcohol beers in our dataset, which are produced through limiting fermentation or by stripping away alcohol via evaporation or dialysis, with both methods having the unintended side-effect of reducing the amount of flavor compounds in the final beer 56 , 57 .
Besides expected associations, our data also reveals less trivial associations between beer styles and specific parameters. For example, geraniol and citronellol, two monoterpenoids responsible for citrus, floral and rose flavors and characteristic of Citra hops, are found in relatively high amounts in Christmas, Saison, and Brett/co-fermented beers, where they may originate from terpenoid-rich spices such as coriander seeds instead of hops 58 .
Tasting panel assessments reveal sensorial relationships in beer
To assess the sensory profile of each beer, a trained tasting panel evaluated each of the 250 beers for 50 sensory attributes, including different hop, malt and yeast flavors, off-flavors and spices. Panelists used a tasting sheet (Supplementary Data 3 ) to score the different attributes. Panel consistency was evaluated by repeating 12 samples across different sessions and performing ANOVA. In 95% of cases no significant difference was found across sessions ( p > 0.05), indicating good panel consistency (Supplementary Table S2 ).
Aroma and taste perception reported by the trained panel are often linked (Fig. 1 , bottom left panel and Supplementary Data 4 and 5 ), with high correlations between hops aroma and taste (Spearman’s rho=0.83). Bitter taste was found to correlate with hop aroma and taste in general (Spearman’s rho=0.80 and 0.69), and particularly with “grassy” noble hops (Spearman’s rho=0.75). Barnyard flavor, most often associated with sour beers, is identified together with stale hops (Spearman’s rho=0.97) that are used in these beers. Lactic and acetic acid, which often co-occur, are correlated (Spearman’s rho=0.66). Interestingly, sweetness and bitterness are anti-correlated (Spearman’s rho = −0.48), confirming the hypothesis that they mask each other 59 , 60 . Beer body is highly correlated with alcohol (Spearman’s rho = 0.79), and overall appreciation is found to correlate with multiple aspects that describe beer mouthfeel (alcohol, carbonation; Spearman’s rho= 0.32, 0.39), as well as with hop and ester aroma intensity (Spearman’s rho=0.39 and 0.35).
Similar to the chemical analyses, sensorial analyses confirmed typical features of specific beer styles (Supplementary Fig. S4 ). For example, sour beers (Faro, Flanders Old Brown, Fruit beer, Kriek, Lambic, West Flanders ale) were rated acidic, with flavors of both acetic and lactic acid. Hoppy beers were found to be bitter and showed hop-associated aromas like citrus and tropical fruit. Malt taste is most detected among scotch, stout/porters, and strong ales, while low/no-alcohol beers, which often have a reputation for being ‘worty’ (reminiscent of unfermented, sweet malt extract) appear in the middle. Unsurprisingly, hop aromas are most strongly detected among hoppy beers. Like its chemical counterpart (Supplementary Fig. S3 ), acidity shows a right-skewed distribution, with the most acidic beers being Krieks, Lambics, and West Flanders ales.
Tasting panel assessments of specific flavors correlate with chemical composition
We find that the concentrations of several chemical compounds strongly correlate with specific aroma or taste, as evaluated by the tasting panel (Fig. 2 , Supplementary Fig. S5 , Supplementary Data 6 ). In some cases, these correlations confirm expectations and serve as a useful control for data quality. For example, iso-alpha acids, the bittering compounds in hops, strongly correlate with bitterness (Spearman’s rho=0.68), while ethanol and glycerol correlate with tasters’ perceptions of alcohol and body, the mouthfeel sensation of fullness (Spearman’s rho=0.82/0.62 and 0.72/0.57 respectively) and darker color from roasted malts is a good indication of malt perception (Spearman’s rho=0.54).

Heatmap colors indicate Spearman’s Rho. Axes are organized according to sensory categories (aroma, taste, mouthfeel, overall), chemical categories and chemical sources in beer (malt (blue), hops (green), yeast (red), wild flora (yellow), Others (black)). See Supplementary Data 6 for all correlation values.
Interestingly, for some relationships between chemical compounds and perceived flavor, correlations are weaker than expected. For example, the rose-smelling phenethyl acetate only weakly correlates with floral aroma. This hints at more complex relationships and interactions between compounds and suggests a need for a more complex model than simple correlations. Lastly, we uncovered unexpected correlations. For instance, the esters ethyl decanoate and ethyl octanoate appear to correlate slightly with hop perception and bitterness, possibly due to their fruity flavor. Iron is anti-correlated with hop aromas and bitterness, most likely because it is also anti-correlated with iso-alpha acids. This could be a sign of metal chelation of hop acids 61 , given that our analyses measure unbound hop acids and total iron content, or could result from the higher iron content in dark and Fruit beers, which typically have less hoppy and bitter flavors 62 .
Public consumer reviews complement expert panel data
To complement and expand the sensory data of our trained tasting panel, we collected 180,000 reviews of our 250 beers from the online consumer review platform RateBeer. This provided numerical scores for beer appearance, aroma, taste, palate, overall quality as well as the average overall score.
Public datasets are known to suffer from biases, such as price, cult status and psychological conformity towards previous ratings of a product. For example, prices correlate with appreciation scores for these online consumer reviews (rho=0.49, Supplementary Fig. S6 ), but not for our trained tasting panel (rho=0.19). This suggests that prices affect consumer appreciation, which has been reported in wine 63 , while blind tastings are unaffected. Moreover, we observe that some beer styles, like lagers and non-alcoholic beers, generally receive lower scores, reflecting that online reviewers are mostly beer aficionados with a preference for specialty beers over lager beers. In general, we find a modest correlation between our trained panel’s overall appreciation score and the online consumer appreciation scores (Fig. 3 , rho=0.29). Apart from the aforementioned biases in the online datasets, serving temperature, sample freshness and surroundings, which are all tightly controlled during the tasting panel sessions, can vary tremendously across online consumers and can further contribute to (among others, appreciation) differences between the two categories of tasters. Importantly, in contrast to the overall appreciation scores, for many sensory aspects the results from the professional panel correlated well with results obtained from RateBeer reviews. Correlations were highest for features that are relatively easy to recognize even for untrained tasters, like bitterness, sweetness, alcohol and malt aroma (Fig. 3 and below).

RateBeer text mining results can be found in Supplementary Data 7 . Rho values shown are Spearman correlation values, with asterisks indicating significant correlations ( p < 0.05, two-sided). All p values were smaller than 0.001, except for Esters aroma (0.0553), Esters taste (0.3275), Esters aroma—banana (0.0019), Coriander (0.0508) and Diacetyl (0.0134).
Besides collecting consumer appreciation from these online reviews, we developed automated text analysis tools to gather additional data from review texts (Supplementary Data 7 ). Processing review texts on the RateBeer database yielded comparable results to the scores given by the trained panel for many common sensory aspects, including acidity, bitterness, sweetness, alcohol, malt, and hop tastes (Fig. 3 ). This is in line with what would be expected, since these attributes require less training for accurate assessment and are less influenced by environmental factors such as temperature, serving glass and odors in the environment. Consumer reviews also correlate well with our trained panel for 4-vinyl guaiacol, a compound associated with a very characteristic aroma. By contrast, correlations for more specific aromas like ester, coriander or diacetyl are underrepresented in the online reviews, underscoring the importance of using a trained tasting panel and standardized tasting sheets with explicit factors to be scored for evaluating specific aspects of a beer. Taken together, our results suggest that public reviews are trustworthy for some, but not all, flavor features and can complement or substitute taste panel data for these sensory aspects.
Models can predict beer sensory profiles from chemical data
The rich datasets of chemical analyses, tasting panel assessments and public reviews gathered in the first part of this study provided us with a unique opportunity to develop predictive models that link chemical data to sensorial features. Given the complexity of beer flavor, basic statistical tools such as correlations or linear regression may not always be the most suitable for making accurate predictions. Instead, we applied different machine learning models that can model both simple linear and complex interactive relationships. Specifically, we constructed a set of regression models to predict (a) trained panel scores for beer flavor and quality and (b) public reviews’ appreciation scores from beer chemical profiles. We trained and tested 10 different models (Methods), 3 linear regression-based models (simple linear regression with first-order interactions (LR), lasso regression with first-order interactions (Lasso), partial least squares regressor (PLSR)), 5 decision tree models (AdaBoost regressor (ABR), extra trees (ET), gradient boosting regressor (GBR), random forest (RF) and XGBoost regressor (XGBR)), 1 support vector regression (SVR), and 1 artificial neural network (ANN) model.
To compare the performance of our machine learning models, the dataset was randomly split into a training and test set, stratified by beer style. After a model was trained on data in the training set, its performance was evaluated on its ability to predict the test dataset obtained from multi-output models (based on the coefficient of determination, see Methods). Additionally, individual-attribute models were ranked per descriptor and the average rank was calculated, as proposed by Korneva et al. 64 . Importantly, both ways of evaluating the models’ performance agreed in general. Performance of the different models varied (Table 1 ). It should be noted that all models perform better at predicting RateBeer results than results from our trained tasting panel. One reason could be that sensory data is inherently variable, and this variability is averaged out with the large number of public reviews from RateBeer. Additionally, all tree-based models perform better at predicting taste than aroma. Linear models (LR) performed particularly poorly, with negative R 2 values, due to severe overfitting (training set R 2 = 1). Overfitting is a common issue in linear models with many parameters and limited samples, especially with interaction terms further amplifying the number of parameters. L1 regularization (Lasso) successfully overcomes this overfitting, out-competing multiple tree-based models on the RateBeer dataset. Similarly, the dimensionality reduction of PLSR avoids overfitting and improves performance, to some extent. Still, tree-based models (ABR, ET, GBR, RF and XGBR) show the best performance, out-competing the linear models (LR, Lasso, PLSR) commonly used in sensory science 65 .
GBR models showed the best overall performance in predicting sensory responses from chemical information, with R 2 values up to 0.75 depending on the predicted sensory feature (Supplementary Table S4 ). The GBR models predict consumer appreciation (RateBeer) better than our trained panel’s appreciation (R 2 value of 0.67 compared to R 2 value of 0.09) (Supplementary Table S3 and Supplementary Table S4 ). ANN models showed intermediate performance, likely because neural networks typically perform best with larger datasets 66 . The SVR shows intermediate performance, mostly due to the weak predictions of specific attributes that lower the overall performance (Supplementary Table S4 ).
Model dissection identifies specific, unexpected compounds as drivers of consumer appreciation
Next, we leveraged our models to infer important contributors to sensory perception and consumer appreciation. Consumer preference is a crucial sensory aspects, because a product that shows low consumer appreciation scores often does not succeed commercially 25 . Additionally, the requirement for a large number of representative evaluators makes consumer trials one of the more costly and time-consuming aspects of product development. Hence, a model for predicting chemical drivers of overall appreciation would be a welcome addition to the available toolbox for food development and optimization.
Since GBR models on our RateBeer dataset showed the best overall performance, we focused on these models. Specifically, we used two approaches to identify important contributors. First, rankings of the most important predictors for each sensorial trait in the GBR models were obtained based on impurity-based feature importance (mean decrease in impurity). High-ranked parameters were hypothesized to be either the true causal chemical properties underlying the trait, to correlate with the actual causal properties, or to take part in sensory interactions affecting the trait 67 (Fig. 4A ). In a second approach, we used SHAP 68 to determine which parameters contributed most to the model for making predictions of consumer appreciation (Fig. 4B ). SHAP calculates parameter contributions to model predictions on a per-sample basis, which can be aggregated into an importance score.

A The impurity-based feature importance (mean deviance in impurity, MDI) calculated from the Gradient Boosting Regression (GBR) model predicting RateBeer appreciation scores. The top 15 highest ranked chemical properties are shown. B SHAP summary plot for the top 15 parameters contributing to our GBR model. Each point on the graph represents a sample from our dataset. The color represents the concentration of that parameter, with bluer colors representing low values and redder colors representing higher values. Greater absolute values on the horizontal axis indicate a higher impact of the parameter on the prediction of the model. C Spearman correlations between the 15 most important chemical properties and consumer overall appreciation. Numbers indicate the Spearman Rho correlation coefficient, and the rank of this correlation compared to all other correlations. The top 15 important compounds were determined using SHAP (panel B).
Both approaches identified ethyl acetate as the most predictive parameter for beer appreciation (Fig. 4 ). Ethyl acetate is the most abundant ester in beer with a typical ‘fruity’, ‘solvent’ and ‘alcoholic’ flavor, but is often considered less important than other esters like isoamyl acetate. The second most important parameter identified by SHAP is ethanol, the most abundant beer compound after water. Apart from directly contributing to beer flavor and mouthfeel, ethanol drastically influences the physical properties of beer, dictating how easily volatile compounds escape the beer matrix to contribute to beer aroma 69 . Importantly, it should also be noted that the importance of ethanol for appreciation is likely inflated by the very low appreciation scores of non-alcoholic beers (Supplementary Fig. S4 ). Despite not often being considered a driver of beer appreciation, protein level also ranks highly in both approaches, possibly due to its effect on mouthfeel and body 70 . Lactic acid, which contributes to the tart taste of sour beers, is the fourth most important parameter identified by SHAP, possibly due to the generally high appreciation of sour beers in our dataset.
Interestingly, some of the most important predictive parameters for our model are not well-established as beer flavors or are even commonly regarded as being negative for beer quality. For example, our models identify methanethiol and ethyl phenyl acetate, an ester commonly linked to beer staling 71 , as a key factor contributing to beer appreciation. Although there is no doubt that high concentrations of these compounds are considered unpleasant, the positive effects of modest concentrations are not yet known 72 , 73 .
To compare our approach to conventional statistics, we evaluated how well the 15 most important SHAP-derived parameters correlate with consumer appreciation (Fig. 4C ). Interestingly, only 6 of the properties derived by SHAP rank amongst the top 15 most correlated parameters. For some chemical compounds, the correlations are so low that they would have likely been considered unimportant. For example, lactic acid, the fourth most important parameter, shows a bimodal distribution for appreciation, with sour beers forming a separate cluster, that is missed entirely by the Spearman correlation. Additionally, the correlation plots reveal outliers, emphasizing the need for robust analysis tools. Together, this highlights the need for alternative models, like the Gradient Boosting model, that better grasp the complexity of (beer) flavor.
Finally, to observe the relationships between these chemical properties and their predicted targets, partial dependence plots were constructed for the six most important predictors of consumer appreciation 74 , 75 , 76 (Supplementary Fig. S7 ). One-way partial dependence plots show how a change in concentration affects the predicted appreciation. These plots reveal an important limitation of our models: appreciation predictions remain constant at ever-increasing concentrations. This implies that once a threshold concentration is reached, further increasing the concentration does not affect appreciation. This is false, as it is well-documented that certain compounds become unpleasant at high concentrations, including ethyl acetate (‘nail polish’) 77 and methanethiol (‘sulfury’ and ‘rotten cabbage’) 78 . The inability of our models to grasp that flavor compounds have optimal levels, above which they become negative, is a consequence of working with commercial beer brands where (off-)flavors are rarely too high to negatively impact the product. The two-way partial dependence plots show how changing the concentration of two compounds influences predicted appreciation, visualizing their interactions (Supplementary Fig. S7 ). In our case, the top 5 parameters are dominated by additive or synergistic interactions, with high concentrations for both compounds resulting in the highest predicted appreciation.
To assess the robustness of our best-performing models and model predictions, we performed 100 iterations of the GBR, RF and ET models. In general, all iterations of the models yielded similar performance (Supplementary Fig. S8 ). Moreover, the main predictors (including the top predictors ethanol and ethyl acetate) remained virtually the same, especially for GBR and RF. For the iterations of the ET model, we did observe more variation in the top predictors, which is likely a consequence of the model’s inherent random architecture in combination with co-correlations between certain predictors. However, even in this case, several of the top predictors (ethanol and ethyl acetate) remain unchanged, although their rank in importance changes (Supplementary Fig. S8 ).
Next, we investigated if a combination of RateBeer and trained panel data into one consolidated dataset would lead to stronger models, under the hypothesis that such a model would suffer less from bias in the datasets. A GBR model was trained to predict appreciation on the combined dataset. This model underperformed compared to the RateBeer model, both in the native case and when including a dataset identifier (R 2 = 0.67, 0.26 and 0.42 respectively). For the latter, the dataset identifier is the most important feature (Supplementary Fig. S9 ), while most of the feature importance remains unchanged, with ethyl acetate and ethanol ranking highest, like in the original model trained only on RateBeer data. It seems that the large variation in the panel dataset introduces noise, weakening the models’ performances and reliability. In addition, it seems reasonable to assume that both datasets are fundamentally different, with the panel dataset obtained by blind tastings by a trained professional panel.
Lastly, we evaluated whether beer style identifiers would further enhance the model’s performance. A GBR model was trained with parameters that explicitly encoded the styles of the samples. This did not improve model performance (R2 = 0.66 with style information vs R2 = 0.67). The most important chemical features are consistent with the model trained without style information (eg. ethanol and ethyl acetate), and with the exception of the most preferred (strong ale) and least preferred (low/no-alcohol) styles, none of the styles were among the most important features (Supplementary Fig. S9 , Supplementary Table S5 and S6 ). This is likely due to a combination of style-specific chemical signatures, such as iso-alpha acids and lactic acid, that implicitly convey style information to the original models, as well as the low number of samples belonging to some styles, making it difficult for the model to learn style-specific patterns. Moreover, beer styles are not rigorously defined, with some styles overlapping in features and some beers being misattributed to a specific style, all of which leads to more noise in models that use style parameters.
Model validation
To test if our predictive models give insight into beer appreciation, we set up experiments aimed at improving existing commercial beers. We specifically selected overall appreciation as the trait to be examined because of its complexity and commercial relevance. Beer flavor comprises a complex bouquet rather than single aromas and tastes 53 . Hence, adding a single compound to the extent that a difference is noticeable may lead to an unbalanced, artificial flavor. Therefore, we evaluated the effect of combinations of compounds. Because Blond beers represent the most extensive style in our dataset, we selected a beer from this style as the starting material for these experiments (Beer 64 in Supplementary Data 1 ).
In the first set of experiments, we adjusted the concentrations of compounds that made up the most important predictors of overall appreciation (ethyl acetate, ethanol, lactic acid, ethyl phenyl acetate) together with correlated compounds (ethyl hexanoate, isoamyl acetate, glycerol), bringing them up to 95 th percentile ethanol-normalized concentrations (Methods) within the Blond group (‘Spiked’ concentration in Fig. 5A ). Compared to controls, the spiked beers were found to have significantly improved overall appreciation among trained panelists, with panelist noting increased intensity of ester flavors, sweetness, alcohol, and body fullness (Fig. 5B ). To disentangle the contribution of ethanol to these results, a second experiment was performed without the addition of ethanol. This resulted in a similar outcome, including increased perception of alcohol and overall appreciation.

Adding the top chemical compounds, identified as best predictors of appreciation by our model, into poorly appreciated beers results in increased appreciation from our trained panel. Results of sensory tests between base beers and those spiked with compounds identified as the best predictors by the model. A Blond and Non/Low-alcohol (0.0% ABV) base beers were brought up to 95th-percentile ethanol-normalized concentrations within each style. B For each sensory attribute, tasters indicated the more intense sample and selected the sample they preferred. The numbers above the bars correspond to the p values that indicate significant changes in perceived flavor (two-sided binomial test: alpha 0.05, n = 20 or 13).
In a last experiment, we tested whether using the model’s predictions can boost the appreciation of a non-alcoholic beer (beer 223 in Supplementary Data 1 ). Again, the addition of a mixture of predicted compounds (omitting ethanol, in this case) resulted in a significant increase in appreciation, body, ester flavor and sweetness.
Predicting flavor and consumer appreciation from chemical composition is one of the ultimate goals of sensory science. A reliable, systematic and unbiased way to link chemical profiles to flavor and food appreciation would be a significant asset to the food and beverage industry. Such tools would substantially aid in quality control and recipe development, offer an efficient and cost-effective alternative to pilot studies and consumer trials and would ultimately allow food manufacturers to produce superior, tailor-made products that better meet the demands of specific consumer groups more efficiently.
A limited set of studies have previously tried, to varying degrees of success, to predict beer flavor and beer popularity based on (a limited set of) chemical compounds and flavors 79 , 80 . Current sensitive, high-throughput technologies allow measuring an unprecedented number of chemical compounds and properties in a large set of samples, yielding a dataset that can train models that help close the gaps between chemistry and flavor, even for a complex natural product like beer. To our knowledge, no previous research gathered data at this scale (250 samples, 226 chemical parameters, 50 sensory attributes and 5 consumer scores) to disentangle and validate the chemical aspects driving beer preference using various machine-learning techniques. We find that modern machine learning models outperform conventional statistical tools, such as correlations and linear models, and can successfully predict flavor appreciation from chemical composition. This could be attributed to the natural incorporation of interactions and non-linear or discontinuous effects in machine learning models, which are not easily grasped by the linear model architecture. While linear models and partial least squares regression represent the most widespread statistical approaches in sensory science, in part because they allow interpretation 65 , 81 , 82 , modern machine learning methods allow for building better predictive models while preserving the possibility to dissect and exploit the underlying patterns. Of the 10 different models we trained, tree-based models, such as our best performing GBR, showed the best overall performance in predicting sensory responses from chemical information, outcompeting artificial neural networks. This agrees with previous reports for models trained on tabular data 83 . Our results are in line with the findings of Colantonio et al. who also identified the gradient boosting architecture as performing best at predicting appreciation and flavor (of tomatoes and blueberries, in their specific study) 26 . Importantly, besides our larger experimental scale, we were able to directly confirm our models’ predictions in vivo.
Our study confirms that flavor compound concentration does not always correlate with perception, suggesting complex interactions that are often missed by more conventional statistics and simple models. Specifically, we find that tree-based algorithms may perform best in developing models that link complex food chemistry with aroma. Furthermore, we show that massive datasets of untrained consumer reviews provide a valuable source of data, that can complement or even replace trained tasting panels, especially for appreciation and basic flavors, such as sweetness and bitterness. This holds despite biases that are known to occur in such datasets, such as price or conformity bias. Moreover, GBR models predict taste better than aroma. This is likely because taste (e.g. bitterness) often directly relates to the corresponding chemical measurements (e.g., iso-alpha acids), whereas such a link is less clear for aromas, which often result from the interplay between multiple volatile compounds. We also find that our models are best at predicting acidity and alcohol, likely because there is a direct relation between the measured chemical compounds (acids and ethanol) and the corresponding perceived sensorial attribute (acidity and alcohol), and because even untrained consumers are generally able to recognize these flavors and aromas.
The predictions of our final models, trained on review data, hold even for blind tastings with small groups of trained tasters, as demonstrated by our ability to validate specific compounds as drivers of beer flavor and appreciation. Since adding a single compound to the extent of a noticeable difference may result in an unbalanced flavor profile, we specifically tested our identified key drivers as a combination of compounds. While this approach does not allow us to validate if a particular single compound would affect flavor and/or appreciation, our experiments do show that this combination of compounds increases consumer appreciation.
It is important to stress that, while it represents an important step forward, our approach still has several major limitations. A key weakness of the GBR model architecture is that amongst co-correlating variables, the largest main effect is consistently preferred for model building. As a result, co-correlating variables often have artificially low importance scores, both for impurity and SHAP-based methods, like we observed in the comparison to the more randomized Extra Trees models. This implies that chemicals identified as key drivers of a specific sensory feature by GBR might not be the true causative compounds, but rather co-correlate with the actual causative chemical. For example, the high importance of ethyl acetate could be (partially) attributed to the total ester content, ethanol or ethyl hexanoate (rho=0.77, rho=0.72 and rho=0.68), while ethyl phenylacetate could hide the importance of prenyl isobutyrate and ethyl benzoate (rho=0.77 and rho=0.76). Expanding our GBR model to include beer style as a parameter did not yield additional power or insight. This is likely due to style-specific chemical signatures, such as iso-alpha acids and lactic acid, that implicitly convey style information to the original model, as well as the smaller sample size per style, limiting the power to uncover style-specific patterns. This can be partly attributed to the curse of dimensionality, where the high number of parameters results in the models mainly incorporating single parameter effects, rather than complex interactions such as style-dependent effects 67 . A larger number of samples may overcome some of these limitations and offer more insight into style-specific effects. On the other hand, beer style is not a rigid scientific classification, and beers within one style often differ a lot, which further complicates the analysis of style as a model factor.
Our study is limited to beers from Belgian breweries. Although these beers cover a large portion of the beer styles available globally, some beer styles and consumer patterns may be missing, while other features might be overrepresented. For example, many Belgian ales exhibit yeast-driven flavor profiles, which is reflected in the chemical drivers of appreciation discovered by this study. In future work, expanding the scope to include diverse markets and beer styles could lead to the identification of even more drivers of appreciation and better models for special niche products that were not present in our beer set.
In addition to inherent limitations of GBR models, there are also some limitations associated with studying food aroma. Even if our chemical analyses measured most of the known aroma compounds, the total number of flavor compounds in complex foods like beer is still larger than the subset we were able to measure in this study. For example, hop-derived thiols, that influence flavor at very low concentrations, are notoriously difficult to measure in a high-throughput experiment. Moreover, consumer perception remains subjective and prone to biases that are difficult to avoid. It is also important to stress that the models are still immature and that more extensive datasets will be crucial for developing more complete models in the future. Besides more samples and parameters, our dataset does not include any demographic information about the tasters. Including such data could lead to better models that grasp external factors like age and culture. Another limitation is that our set of beers consists of high-quality end-products and lacks beers that are unfit for sale, which limits the current model in accurately predicting products that are appreciated very badly. Finally, while models could be readily applied in quality control, their use in sensory science and product development is restrained by their inability to discern causal relationships. Given that the models cannot distinguish compounds that genuinely drive consumer perception from those that merely correlate, validation experiments are essential to identify true causative compounds.
Despite the inherent limitations, dissection of our models enabled us to pinpoint specific molecules as potential drivers of beer aroma and consumer appreciation, including compounds that were unexpected and would not have been identified using standard approaches. Important drivers of beer appreciation uncovered by our models include protein levels, ethyl acetate, ethyl phenyl acetate and lactic acid. Currently, many brewers already use lactic acid to acidify their brewing water and ensure optimal pH for enzymatic activity during the mashing process. Our results suggest that adding lactic acid can also improve beer appreciation, although its individual effect remains to be tested. Interestingly, ethanol appears to be unnecessary to improve beer appreciation, both for blond beer and alcohol-free beer. Given the growing consumer interest in alcohol-free beer, with a predicted annual market growth of >7% 84 , it is relevant for brewers to know what compounds can further increase consumer appreciation of these beers. Hence, our model may readily provide avenues to further improve the flavor and consumer appreciation of both alcoholic and non-alcoholic beers, which is generally considered one of the key challenges for future beer production.
Whereas we see a direct implementation of our results for the development of superior alcohol-free beverages and other food products, our study can also serve as a stepping stone for the development of novel alcohol-containing beverages. We want to echo the growing body of scientific evidence for the negative effects of alcohol consumption, both on the individual level by the mutagenic, teratogenic and carcinogenic effects of ethanol 85 , 86 , as well as the burden on society caused by alcohol abuse and addiction. We encourage the use of our results for the production of healthier, tastier products, including novel and improved beverages with lower alcohol contents. Furthermore, we strongly discourage the use of these technologies to improve the appreciation or addictive properties of harmful substances.
The present work demonstrates that despite some important remaining hurdles, combining the latest developments in chemical analyses, sensory analysis and modern machine learning methods offers exciting avenues for food chemistry and engineering. Soon, these tools may provide solutions in quality control and recipe development, as well as new approaches to sensory science and flavor research.
Beer selection
250 commercial Belgian beers were selected to cover the broad diversity of beer styles and corresponding diversity in chemical composition and aroma. See Supplementary Fig. S1 .
Chemical dataset
Sample preparation.
Beers within their expiration date were purchased from commercial retailers. Samples were prepared in biological duplicates at room temperature, unless explicitly stated otherwise. Bottle pressure was measured with a manual pressure device (Steinfurth Mess-Systeme GmbH) and used to calculate CO 2 concentration. The beer was poured through two filter papers (Macherey-Nagel, 500713032 MN 713 ¼) to remove carbon dioxide and prevent spontaneous foaming. Samples were then prepared for measurements by targeted Headspace-Gas Chromatography-Flame Ionization Detector/Flame Photometric Detector (HS-GC-FID/FPD), Headspace-Solid Phase Microextraction-Gas Chromatography-Mass Spectrometry (HS-SPME-GC-MS), colorimetric analysis, enzymatic analysis, Near-Infrared (NIR) analysis, as described in the sections below. The mean values of biological duplicates are reported for each compound.
HS-GC-FID/FPD
HS-GC-FID/FPD (Shimadzu GC 2010 Plus) was used to measure higher alcohols, acetaldehyde, esters, 4-vinyl guaicol, and sulfur compounds. Each measurement comprised 5 ml of sample pipetted into a 20 ml glass vial containing 1.75 g NaCl (VWR, 27810.295). 100 µl of 2-heptanol (Sigma-Aldrich, H3003) (internal standard) solution in ethanol (Fisher Chemical, E/0650DF/C17) was added for a final concentration of 2.44 mg/L. Samples were flushed with nitrogen for 10 s, sealed with a silicone septum, stored at −80 °C and analyzed in batches of 20.
The GC was equipped with a DB-WAXetr column (length, 30 m; internal diameter, 0.32 mm; layer thickness, 0.50 µm; Agilent Technologies, Santa Clara, CA, USA) to the FID and an HP-5 column (length, 30 m; internal diameter, 0.25 mm; layer thickness, 0.25 µm; Agilent Technologies, Santa Clara, CA, USA) to the FPD. N 2 was used as the carrier gas. Samples were incubated for 20 min at 70 °C in the headspace autosampler (Flow rate, 35 cm/s; Injection volume, 1000 µL; Injection mode, split; Combi PAL autosampler, CTC analytics, Switzerland). The injector, FID and FPD temperatures were kept at 250 °C. The GC oven temperature was first held at 50 °C for 5 min and then allowed to rise to 80 °C at a rate of 5 °C/min, followed by a second ramp of 4 °C/min until 200 °C kept for 3 min and a final ramp of (4 °C/min) until 230 °C for 1 min. Results were analyzed with the GCSolution software version 2.4 (Shimadzu, Kyoto, Japan). The GC was calibrated with a 5% EtOH solution (VWR International) containing the volatiles under study (Supplementary Table S7 ).
HS-SPME-GC-MS
HS-SPME-GC-MS (Shimadzu GCMS-QP-2010 Ultra) was used to measure additional volatile compounds, mainly comprising terpenoids and esters. Samples were analyzed by HS-SPME using a triphase DVB/Carboxen/PDMS 50/30 μm SPME fiber (Supelco Co., Bellefonte, PA, USA) followed by gas chromatography (Thermo Fisher Scientific Trace 1300 series, USA) coupled to a mass spectrometer (Thermo Fisher Scientific ISQ series MS) equipped with a TriPlus RSH autosampler. 5 ml of degassed beer sample was placed in 20 ml vials containing 1.75 g NaCl (VWR, 27810.295). 5 µl internal standard mix was added, containing 2-heptanol (1 g/L) (Sigma-Aldrich, H3003), 4-fluorobenzaldehyde (1 g/L) (Sigma-Aldrich, 128376), 2,3-hexanedione (1 g/L) (Sigma-Aldrich, 144169) and guaiacol (1 g/L) (Sigma-Aldrich, W253200) in ethanol (Fisher Chemical, E/0650DF/C17). Each sample was incubated at 60 °C in the autosampler oven with constant agitation. After 5 min equilibration, the SPME fiber was exposed to the sample headspace for 30 min. The compounds trapped on the fiber were thermally desorbed in the injection port of the chromatograph by heating the fiber for 15 min at 270 °C.
The GC-MS was equipped with a low polarity RXi-5Sil MS column (length, 20 m; internal diameter, 0.18 mm; layer thickness, 0.18 µm; Restek, Bellefonte, PA, USA). Injection was performed in splitless mode at 320 °C, a split flow of 9 ml/min, a purge flow of 5 ml/min and an open valve time of 3 min. To obtain a pulsed injection, a programmed gas flow was used whereby the helium gas flow was set at 2.7 mL/min for 0.1 min, followed by a decrease in flow of 20 ml/min to the normal 0.9 mL/min. The temperature was first held at 30 °C for 3 min and then allowed to rise to 80 °C at a rate of 7 °C/min, followed by a second ramp of 2 °C/min till 125 °C and a final ramp of 8 °C/min with a final temperature of 270 °C.
Mass acquisition range was 33 to 550 amu at a scan rate of 5 scans/s. Electron impact ionization energy was 70 eV. The interface and ion source were kept at 275 °C and 250 °C, respectively. A mix of linear n-alkanes (from C7 to C40, Supelco Co.) was injected into the GC-MS under identical conditions to serve as external retention index markers. Identification and quantification of the compounds were performed using an in-house developed R script as described in Goelen et al. and Reher et al. 87 , 88 (for package information, see Supplementary Table S8 ). Briefly, chromatograms were analyzed using AMDIS (v2.71) 89 to separate overlapping peaks and obtain pure compound spectra. The NIST MS Search software (v2.0 g) in combination with the NIST2017, FFNSC3 and Adams4 libraries were used to manually identify the empirical spectra, taking into account the expected retention time. After background subtraction and correcting for retention time shifts between samples run on different days based on alkane ladders, compound elution profiles were extracted and integrated using a file with 284 target compounds of interest, which were either recovered in our identified AMDIS list of spectra or were known to occur in beer. Compound elution profiles were estimated for every peak in every chromatogram over a time-restricted window using weighted non-negative least square analysis after which peak areas were integrated 87 , 88 . Batch effect correction was performed by normalizing against the most stable internal standard compound, 4-fluorobenzaldehyde. Out of all 284 target compounds that were analyzed, 167 were visually judged to have reliable elution profiles and were used for final analysis.
Discrete photometric and enzymatic analysis
Discrete photometric and enzymatic analysis (Thermo Scientific TM Gallery TM Plus Beermaster Discrete Analyzer) was used to measure acetic acid, ammonia, beta-glucan, iso-alpha acids, color, sugars, glycerol, iron, pH, protein, and sulfite. 2 ml of sample volume was used for the analyses. Information regarding the reagents and standard solutions used for analyses and calibrations is included in Supplementary Table S7 and Supplementary Table S9 .
NIR analyses
NIR analysis (Anton Paar Alcolyzer Beer ME System) was used to measure ethanol. Measurements comprised 50 ml of sample, and a 10% EtOH solution was used for calibration.
Correlation calculations
Pairwise Spearman Rank correlations were calculated between all chemical properties.
Sensory dataset
Trained panel.
Our trained tasting panel consisted of volunteers who gave prior verbal informed consent. All compounds used for the validation experiment were of food-grade quality. The tasting sessions were approved by the Social and Societal Ethics Committee of the KU Leuven (G-2022-5677-R2(MAR)). All online reviewers agreed to the Terms and Conditions of the RateBeer website.
Sensory analysis was performed according to the American Society of Brewing Chemists (ASBC) Sensory Analysis Methods 90 . 30 volunteers were screened through a series of triangle tests. The sixteen most sensitive and consistent tasters were retained as taste panel members. The resulting panel was diverse in age [22–42, mean: 29], sex [56% male] and nationality [7 different countries]. The panel developed a consensus vocabulary to describe beer aroma, taste and mouthfeel. Panelists were trained to identify and score 50 different attributes, using a 7-point scale to rate attributes’ intensity. The scoring sheet is included as Supplementary Data 3 . Sensory assessments took place between 10–12 a.m. The beers were served in black-colored glasses. Per session, between 5 and 12 beers of the same style were tasted at 12 °C to 16 °C. Two reference beers were added to each set and indicated as ‘Reference 1 & 2’, allowing panel members to calibrate their ratings. Not all panelists were present at every tasting. Scores were scaled by standard deviation and mean-centered per taster. Values are represented as z-scores and clustered by Euclidean distance. Pairwise Spearman correlations were calculated between taste and aroma sensory attributes. Panel consistency was evaluated by repeating samples on different sessions and performing ANOVA to identify differences, using the ‘stats’ package (v4.2.2) in R (for package information, see Supplementary Table S8 ).
Online reviews from a public database
The ‘scrapy’ package in Python (v3.6) (for package information, see Supplementary Table S8 ). was used to collect 232,288 online reviews (mean=922, min=6, max=5343) from RateBeer, an online beer review database. Each review entry comprised 5 numerical scores (appearance, aroma, taste, palate and overall quality) and an optional review text. The total number of reviews per reviewer was collected separately. Numerical scores were scaled and centered per rater, and mean scores were calculated per beer.
For the review texts, the language was estimated using the packages ‘langdetect’ and ‘langid’ in Python. Reviews that were classified as English by both packages were kept. Reviewers with fewer than 100 entries overall were discarded. 181,025 reviews from >6000 reviewers from >40 countries remained. Text processing was done using the ‘nltk’ package in Python. Texts were corrected for slang and misspellings; proper nouns and rare words that are relevant to the beer context were specified and kept as-is (‘Chimay’,’Lambic’, etc.). A dictionary of semantically similar sensorial terms, for example ‘floral’ and ‘flower’, was created and collapsed together into one term. Words were stemmed and lemmatized to avoid identifying words such as ‘acid’ and ‘acidity’ as separate terms. Numbers and punctuation were removed.
Sentences from up to 50 randomly chosen reviews per beer were manually categorized according to the aspect of beer they describe (appearance, aroma, taste, palate, overall quality—not to be confused with the 5 numerical scores described above) or flagged as irrelevant if they contained no useful information. If a beer contained fewer than 50 reviews, all reviews were manually classified. This labeled data set was used to train a model that classified the rest of the sentences for all beers 91 . Sentences describing taste and aroma were extracted, and term frequency–inverse document frequency (TFIDF) was implemented to calculate enrichment scores for sensorial words per beer.
The sex of the tasting subject was not considered when building our sensory database. Instead, results from different panelists were averaged, both for our trained panel (56% male, 44% female) and the RateBeer reviews (70% male, 30% female for RateBeer as a whole).
Beer price collection and processing
Beer prices were collected from the following stores: Colruyt, Delhaize, Total Wine, BeerHawk, The Belgian Beer Shop, The Belgian Shop, and Beer of Belgium. Where applicable, prices were converted to Euros and normalized per liter. Spearman correlations were calculated between these prices and mean overall appreciation scores from RateBeer and the taste panel, respectively.
Pairwise Spearman Rank correlations were calculated between all sensory properties.
Machine learning models
Predictive modeling of sensory profiles from chemical data.
Regression models were constructed to predict (a) trained panel scores for beer flavors and quality from beer chemical profiles and (b) public reviews’ appreciation scores from beer chemical profiles. Z-scores were used to represent sensory attributes in both data sets. Chemical properties with log-normal distributions (Shapiro-Wilk test, p < 0.05 ) were log-transformed. Missing chemical measurements (0.1% of all data) were replaced with mean values per attribute. Observations from 250 beers were randomly separated into a training set (70%, 175 beers) and a test set (30%, 75 beers), stratified per beer style. Chemical measurements (p = 231) were normalized based on the training set average and standard deviation. In total, three linear regression-based models: linear regression with first-order interaction terms (LR), lasso regression with first-order interaction terms (Lasso) and partial least squares regression (PLSR); five decision tree models, Adaboost regressor (ABR), Extra Trees (ET), Gradient Boosting regressor (GBR), Random Forest (RF) and XGBoost regressor (XGBR); one support vector machine model (SVR) and one artificial neural network model (ANN) were trained. The models were implemented using the ‘scikit-learn’ package (v1.2.2) and ‘xgboost’ package (v1.7.3) in Python (v3.9.16). Models were trained, and hyperparameters optimized, using five-fold cross-validated grid search with the coefficient of determination (R 2 ) as the evaluation metric. The ANN (scikit-learn’s MLPRegressor) was optimized using Bayesian Tree-Structured Parzen Estimator optimization with the ‘Optuna’ Python package (v3.2.0). Individual models were trained per attribute, and a multi-output model was trained on all attributes simultaneously.
Model dissection
GBR was found to outperform other methods, resulting in models with the highest average R 2 values in both trained panel and public review data sets. Impurity-based rankings of the most important predictors for each predicted sensorial trait were obtained using the ‘scikit-learn’ package. To observe the relationships between these chemical properties and their predicted targets, partial dependence plots (PDP) were constructed for the six most important predictors of consumer appreciation 74 , 75 .
The ‘SHAP’ package in Python (v0.41.0) was implemented to provide an alternative ranking of predictor importance and to visualize the predictors’ effects as a function of their concentration 68 .
Validation of causal chemical properties
To validate the effects of the most important model features on predicted sensory attributes, beers were spiked with the chemical compounds identified by the models and descriptive sensory analyses were carried out according to the American Society of Brewing Chemists (ASBC) protocol 90 .
Compound spiking was done 30 min before tasting. Compounds were spiked into fresh beer bottles, that were immediately resealed and inverted three times. Fresh bottles of beer were opened for the same duration, resealed, and inverted thrice, to serve as controls. Pairs of spiked samples and controls were served simultaneously, chilled and in dark glasses as outlined in the Trained panel section above. Tasters were instructed to select the glass with the higher flavor intensity for each attribute (directional difference test 92 ) and to select the glass they prefer.
The final concentration after spiking was equal to the within-style average, after normalizing by ethanol concentration. This was done to ensure balanced flavor profiles in the final spiked beer. The same methods were applied to improve a non-alcoholic beer. Compounds were the following: ethyl acetate (Merck KGaA, W241415), ethyl hexanoate (Merck KGaA, W243906), isoamyl acetate (Merck KGaA, W205508), phenethyl acetate (Merck KGaA, W285706), ethanol (96%, Colruyt), glycerol (Merck KGaA, W252506), lactic acid (Merck KGaA, 261106).
Significant differences in preference or perceived intensity were determined by performing the two-sided binomial test on each attribute.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data that support the findings of this work are available in the Supplementary Data files and have been deposited to Zenodo under accession code 10653704 93 . The RateBeer scores data are under restricted access, they are not publicly available as they are property of RateBeer (ZX Ventures, USA). Access can be obtained from the authors upon reasonable request and with permission of RateBeer (ZX Ventures, USA). Source data are provided with this paper.
Code availability
The code for training the machine learning models, analyzing the models, and generating the figures has been deposited to Zenodo under accession code 10653704 93 .
Tieman, D. et al. A chemical genetic roadmap to improved tomato flavor. Science 355 , 391–394 (2017).
Article ADS CAS PubMed Google Scholar
Plutowska, B. & Wardencki, W. Application of gas chromatography–olfactometry (GC–O) in analysis and quality assessment of alcoholic beverages – A review. Food Chem. 107 , 449–463 (2008).
Article CAS Google Scholar
Legin, A., Rudnitskaya, A., Seleznev, B. & Vlasov, Y. Electronic tongue for quality assessment of ethanol, vodka and eau-de-vie. Anal. Chim. Acta 534 , 129–135 (2005).
Loutfi, A., Coradeschi, S., Mani, G. K., Shankar, P. & Rayappan, J. B. B. Electronic noses for food quality: A review. J. Food Eng. 144 , 103–111 (2015).
Ahn, Y.-Y., Ahnert, S. E., Bagrow, J. P. & Barabási, A.-L. Flavor network and the principles of food pairing. Sci. Rep. 1 , 196 (2011).
Article CAS PubMed PubMed Central Google Scholar
Bartoshuk, L. M. & Klee, H. J. Better fruits and vegetables through sensory analysis. Curr. Biol. 23 , R374–R378 (2013).
Article CAS PubMed Google Scholar
Piggott, J. R. Design questions in sensory and consumer science. Food Qual. Prefer. 3293 , 217–220 (1995).
Article Google Scholar
Kermit, M. & Lengard, V. Assessing the performance of a sensory panel-panellist monitoring and tracking. J. Chemom. 19 , 154–161 (2005).
Cook, D. J., Hollowood, T. A., Linforth, R. S. T. & Taylor, A. J. Correlating instrumental measurements of texture and flavour release with human perception. Int. J. Food Sci. Technol. 40 , 631–641 (2005).
Chinchanachokchai, S., Thontirawong, P. & Chinchanachokchai, P. A tale of two recommender systems: The moderating role of consumer expertise on artificial intelligence based product recommendations. J. Retail. Consum. Serv. 61 , 1–12 (2021).
Ross, C. F. Sensory science at the human-machine interface. Trends Food Sci. Technol. 20 , 63–72 (2009).
Chambers, E. IV & Koppel, K. Associations of volatile compounds with sensory aroma and flavor: The complex nature of flavor. Molecules 18 , 4887–4905 (2013).
Pinu, F. R. Metabolomics—The new frontier in food safety and quality research. Food Res. Int. 72 , 80–81 (2015).
Danezis, G. P., Tsagkaris, A. S., Brusic, V. & Georgiou, C. A. Food authentication: state of the art and prospects. Curr. Opin. Food Sci. 10 , 22–31 (2016).
Shepherd, G. M. Smell images and the flavour system in the human brain. Nature 444 , 316–321 (2006).
Meilgaard, M. C. Prediction of flavor differences between beers from their chemical composition. J. Agric. Food Chem. 30 , 1009–1017 (1982).
Xu, L. et al. Widespread receptor-driven modulation in peripheral olfactory coding. Science 368 , eaaz5390 (2020).
Kupferschmidt, K. Following the flavor. Science 340 , 808–809 (2013).
Billesbølle, C. B. et al. Structural basis of odorant recognition by a human odorant receptor. Nature 615 , 742–749 (2023).
Article ADS PubMed PubMed Central Google Scholar
Smith, B. Perspective: Complexities of flavour. Nature 486 , S6–S6 (2012).
Pfister, P. et al. Odorant receptor inhibition is fundamental to odor encoding. Curr. Biol. 30 , 2574–2587 (2020).
Moskowitz, H. W., Kumaraiah, V., Sharma, K. N., Jacobs, H. L. & Sharma, S. D. Cross-cultural differences in simple taste preferences. Science 190 , 1217–1218 (1975).
Eriksson, N. et al. A genetic variant near olfactory receptor genes influences cilantro preference. Flavour 1 , 22 (2012).
Ferdenzi, C. et al. Variability of affective responses to odors: Culture, gender, and olfactory knowledge. Chem. Senses 38 , 175–186 (2013).
Article PubMed Google Scholar
Lawless, H. T. & Heymann, H. Sensory evaluation of food: Principles and practices. (Springer, New York, NY). https://doi.org/10.1007/978-1-4419-6488-5 (2010).
Colantonio, V. et al. Metabolomic selection for enhanced fruit flavor. Proc. Natl. Acad. Sci. 119 , e2115865119 (2022).
Fritz, F., Preissner, R. & Banerjee, P. VirtualTaste: a web server for the prediction of organoleptic properties of chemical compounds. Nucleic Acids Res 49 , W679–W684 (2021).
Tuwani, R., Wadhwa, S. & Bagler, G. BitterSweet: Building machine learning models for predicting the bitter and sweet taste of small molecules. Sci. Rep. 9 , 1–13 (2019).
Dagan-Wiener, A. et al. Bitter or not? BitterPredict, a tool for predicting taste from chemical structure. Sci. Rep. 7 , 1–13 (2017).
Pallante, L. et al. Toward a general and interpretable umami taste predictor using a multi-objective machine learning approach. Sci. Rep. 12 , 1–11 (2022).
Malavolta, M. et al. A survey on computational taste predictors. Eur. Food Res. Technol. 248 , 2215–2235 (2022).
Lee, B. K. et al. A principal odor map unifies diverse tasks in olfactory perception. Science 381 , 999–1006 (2023).
Mayhew, E. J. et al. Transport features predict if a molecule is odorous. Proc. Natl. Acad. Sci. 119 , e2116576119 (2022).
Niu, Y. et al. Sensory evaluation of the synergism among ester odorants in light aroma-type liquor by odor threshold, aroma intensity and flash GC electronic nose. Food Res. Int. 113 , 102–114 (2018).
Yu, P., Low, M. Y. & Zhou, W. Design of experiments and regression modelling in food flavour and sensory analysis: A review. Trends Food Sci. Technol. 71 , 202–215 (2018).
Oladokun, O. et al. The impact of hop bitter acid and polyphenol profiles on the perceived bitterness of beer. Food Chem. 205 , 212–220 (2016).
Linforth, R., Cabannes, M., Hewson, L., Yang, N. & Taylor, A. Effect of fat content on flavor delivery during consumption: An in vivo model. J. Agric. Food Chem. 58 , 6905–6911 (2010).
Guo, S., Na Jom, K. & Ge, Y. Influence of roasting condition on flavor profile of sunflower seeds: A flavoromics approach. Sci. Rep. 9 , 11295 (2019).
Ren, Q. et al. The changes of microbial community and flavor compound in the fermentation process of Chinese rice wine using Fagopyrum tataricum grain as feedstock. Sci. Rep. 9 , 3365 (2019).
Hastie, T., Friedman, J. & Tibshirani, R. The Elements of Statistical Learning. (Springer, New York, NY). https://doi.org/10.1007/978-0-387-21606-5 (2001).
Dietz, C., Cook, D., Huismann, M., Wilson, C. & Ford, R. The multisensory perception of hop essential oil: a review. J. Inst. Brew. 126 , 320–342 (2020).
CAS Google Scholar
Roncoroni, Miguel & Verstrepen, Kevin Joan. Belgian Beer: Tested and Tasted. (Lannoo, 2018).
Meilgaard, M. Flavor chemistry of beer: Part II: Flavor and threshold of 239 aroma volatiles. in (1975).
Bokulich, N. A. & Bamforth, C. W. The microbiology of malting and brewing. Microbiol. Mol. Biol. Rev. MMBR 77 , 157–172 (2013).
Dzialo, M. C., Park, R., Steensels, J., Lievens, B. & Verstrepen, K. J. Physiology, ecology and industrial applications of aroma formation in yeast. FEMS Microbiol. Rev. 41 , S95–S128 (2017).
Article PubMed PubMed Central Google Scholar
Datta, A. et al. Computer-aided food engineering. Nat. Food 3 , 894–904 (2022).
American Society of Brewing Chemists. Beer Methods. (American Society of Brewing Chemists, St. Paul, MN, U.S.A.).
Olaniran, A. O., Hiralal, L., Mokoena, M. P. & Pillay, B. Flavour-active volatile compounds in beer: production, regulation and control. J. Inst. Brew. 123 , 13–23 (2017).
Verstrepen, K. J. et al. Flavor-active esters: Adding fruitiness to beer. J. Biosci. Bioeng. 96 , 110–118 (2003).
Meilgaard, M. C. Flavour chemistry of beer. part I: flavour interaction between principal volatiles. Master Brew. Assoc. Am. Tech. Q 12 , 107–117 (1975).
Briggs, D. E., Boulton, C. A., Brookes, P. A. & Stevens, R. Brewing 227–254. (Woodhead Publishing). https://doi.org/10.1533/9781855739062.227 (2004).
Bossaert, S., Crauwels, S., De Rouck, G. & Lievens, B. The power of sour - A review: Old traditions, new opportunities. BrewingScience 72 , 78–88 (2019).
Google Scholar
Verstrepen, K. J. et al. Flavor active esters: Adding fruitiness to beer. J. Biosci. Bioeng. 96 , 110–118 (2003).
Snauwaert, I. et al. Microbial diversity and metabolite composition of Belgian red-brown acidic ales. Int. J. Food Microbiol. 221 , 1–11 (2016).
Spitaels, F. et al. The microbial diversity of traditional spontaneously fermented lambic beer. PLoS ONE 9 , e95384 (2014).
Blanco, C. A., Andrés-Iglesias, C. & Montero, O. Low-alcohol Beers: Flavor Compounds, Defects, and Improvement Strategies. Crit. Rev. Food Sci. Nutr. 56 , 1379–1388 (2016).
Jackowski, M. & Trusek, A. Non-Alcohol. beer Prod. – Overv. 20 , 32–38 (2018).
Takoi, K. et al. The contribution of geraniol metabolism to the citrus flavour of beer: Synergy of geraniol and β-citronellol under coexistence with excess linalool. J. Inst. Brew. 116 , 251–260 (2010).
Kroeze, J. H. & Bartoshuk, L. M. Bitterness suppression as revealed by split-tongue taste stimulation in humans. Physiol. Behav. 35 , 779–783 (1985).
Mennella, J. A. et al. A spoonful of sugar helps the medicine go down”: Bitter masking bysucrose among children and adults. Chem. Senses 40 , 17–25 (2015).
Wietstock, P., Kunz, T., Perreira, F. & Methner, F.-J. Metal chelation behavior of hop acids in buffered model systems. BrewingScience 69 , 56–63 (2016).
Sancho, D., Blanco, C. A., Caballero, I. & Pascual, A. Free iron in pale, dark and alcohol-free commercial lager beers. J. Sci. Food Agric. 91 , 1142–1147 (2011).
Rodrigues, H. & Parr, W. V. Contribution of cross-cultural studies to understanding wine appreciation: A review. Food Res. Int. 115 , 251–258 (2019).
Korneva, E. & Blockeel, H. Towards better evaluation of multi-target regression models. in ECML PKDD 2020 Workshops (eds. Koprinska, I. et al.) 353–362 (Springer International Publishing, Cham, 2020). https://doi.org/10.1007/978-3-030-65965-3_23 .
Gastón Ares. Mathematical and Statistical Methods in Food Science and Technology. (Wiley, 2013).
Grinsztajn, L., Oyallon, E. & Varoquaux, G. Why do tree-based models still outperform deep learning on tabular data? Preprint at http://arxiv.org/abs/2207.08815 (2022).
Gries, S. T. Statistics for Linguistics with R: A Practical Introduction. in Statistics for Linguistics with R (De Gruyter Mouton, 2021). https://doi.org/10.1515/9783110718256 .
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2 , 56–67 (2020).
Ickes, C. M. & Cadwallader, K. R. Effects of ethanol on flavor perception in alcoholic beverages. Chemosens. Percept. 10 , 119–134 (2017).
Kato, M. et al. Influence of high molecular weight polypeptides on the mouthfeel of commercial beer. J. Inst. Brew. 127 , 27–40 (2021).
Wauters, R. et al. Novel Saccharomyces cerevisiae variants slow down the accumulation of staling aldehydes and improve beer shelf-life. Food Chem. 398 , 1–11 (2023).
Li, H., Jia, S. & Zhang, W. Rapid determination of low-level sulfur compounds in beer by headspace gas chromatography with a pulsed flame photometric detector. J. Am. Soc. Brew. Chem. 66 , 188–191 (2008).
Dercksen, A., Laurens, J., Torline, P., Axcell, B. C. & Rohwer, E. Quantitative analysis of volatile sulfur compounds in beer using a membrane extraction interface. J. Am. Soc. Brew. Chem. 54 , 228–233 (1996).
Molnar, C. Interpretable Machine Learning: A Guide for Making Black-Box Models Interpretable. (2020).
Zhao, Q. & Hastie, T. Causal interpretations of black-box models. J. Bus. Econ. Stat. Publ. Am. Stat. Assoc. 39 , 272–281 (2019).
Article MathSciNet Google Scholar
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning. (Springer, 2019).
Labrado, D. et al. Identification by NMR of key compounds present in beer distillates and residual phases after dealcoholization by vacuum distillation. J. Sci. Food Agric. 100 , 3971–3978 (2020).
Lusk, L. T., Kay, S. B., Porubcan, A. & Ryder, D. S. Key olfactory cues for beer oxidation. J. Am. Soc. Brew. Chem. 70 , 257–261 (2012).
Gonzalez Viejo, C., Torrico, D. D., Dunshea, F. R. & Fuentes, S. Development of artificial neural network models to assess beer acceptability based on sensory properties using a robotic pourer: A comparative model approach to achieve an artificial intelligence system. Beverages 5 , 33 (2019).
Gonzalez Viejo, C., Fuentes, S., Torrico, D. D., Godbole, A. & Dunshea, F. R. Chemical characterization of aromas in beer and their effect on consumers liking. Food Chem. 293 , 479–485 (2019).
Gilbert, J. L. et al. Identifying breeding priorities for blueberry flavor using biochemical, sensory, and genotype by environment analyses. PLOS ONE 10 , 1–21 (2015).
Goulet, C. et al. Role of an esterase in flavor volatile variation within the tomato clade. Proc. Natl. Acad. Sci. 109 , 19009–19014 (2012).
Article ADS CAS PubMed PubMed Central Google Scholar
Borisov, V. et al. Deep Neural Networks and Tabular Data: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 1–21 https://doi.org/10.1109/TNNLS.2022.3229161 (2022).
Statista. Statista Consumer Market Outlook: Beer - Worldwide.
Seitz, H. K. & Stickel, F. Molecular mechanisms of alcoholmediated carcinogenesis. Nat. Rev. Cancer 7 , 599–612 (2007).
Voordeckers, K. et al. Ethanol exposure increases mutation rate through error-prone polymerases. Nat. Commun. 11 , 3664 (2020).
Goelen, T. et al. Bacterial phylogeny predicts volatile organic compound composition and olfactory response of an aphid parasitoid. Oikos 129 , 1415–1428 (2020).
Article ADS Google Scholar
Reher, T. et al. Evaluation of hop (Humulus lupulus) as a repellent for the management of Drosophila suzukii. Crop Prot. 124 , 104839 (2019).
Stein, S. E. An integrated method for spectrum extraction and compound identification from gas chromatography/mass spectrometry data. J. Am. Soc. Mass Spectrom. 10 , 770–781 (1999).
American Society of Brewing Chemists. Sensory Analysis Methods. (American Society of Brewing Chemists, St. Paul, MN, U.S.A., 1992).
McAuley, J., Leskovec, J. & Jurafsky, D. Learning Attitudes and Attributes from Multi-Aspect Reviews. Preprint at https://doi.org/10.48550/arXiv.1210.3926 (2012).
Meilgaard, M. C., Carr, B. T. & Carr, B. T. Sensory Evaluation Techniques. (CRC Press, Boca Raton). https://doi.org/10.1201/b16452 (2014).
Schreurs, M. et al. Data from: Predicting and improving complex beer flavor through machine learning. Zenodo https://doi.org/10.5281/zenodo.10653704 (2024).
Download references
Acknowledgements
We thank all lab members for their discussions and thank all tasting panel members for their contributions. Special thanks go out to Dr. Karin Voordeckers for her tremendous help in proofreading and improving the manuscript. M.S. was supported by a Baillet-Latour fellowship, L.C. acknowledges financial support from KU Leuven (C16/17/006), F.A.T. was supported by a PhD fellowship from FWO (1S08821N). Research in the lab of K.J.V. is supported by KU Leuven, FWO, VIB, VLAIO and the Brewing Science Serves Health Fund. Research in the lab of T.W. is supported by FWO (G.0A51.15) and KU Leuven (C16/17/006).
Author information
These authors contributed equally: Michiel Schreurs, Supinya Piampongsant, Miguel Roncoroni.
Authors and Affiliations
VIB—KU Leuven Center for Microbiology, Gaston Geenslaan 1, B-3001, Leuven, Belgium
Michiel Schreurs, Supinya Piampongsant, Miguel Roncoroni, Lloyd Cool, Beatriz Herrera-Malaver, Florian A. Theßeling & Kevin J. Verstrepen
CMPG Laboratory of Genetics and Genomics, KU Leuven, Gaston Geenslaan 1, B-3001, Leuven, Belgium
Leuven Institute for Beer Research (LIBR), Gaston Geenslaan 1, B-3001, Leuven, Belgium
Laboratory of Socioecology and Social Evolution, KU Leuven, Naamsestraat 59, B-3000, Leuven, Belgium
Lloyd Cool, Christophe Vanderaa & Tom Wenseleers
VIB Bioinformatics Core, VIB, Rijvisschestraat 120, B-9052, Ghent, Belgium
Łukasz Kreft & Alexander Botzki
AB InBev SA/NV, Brouwerijplein 1, B-3000, Leuven, Belgium
Philippe Malcorps & Luk Daenen
You can also search for this author in PubMed Google Scholar
Contributions
S.P., M.S. and K.J.V. conceived the experiments. S.P., M.S. and K.J.V. designed the experiments. S.P., M.S., M.R., B.H. and F.A.T. performed the experiments. S.P., M.S., L.C., C.V., L.K., A.B., P.M., L.D., T.W. and K.J.V. contributed analysis ideas. S.P., M.S., L.C., C.V., T.W. and K.J.V. analyzed the data. All authors contributed to writing the manuscript.
Corresponding author
Correspondence to Kevin J. Verstrepen .
Ethics declarations
Competing interests.
K.J.V. is affiliated with bar.on. The other authors declare no competing interests.
Peer review
Peer review information.
Nature Communications thanks Florian Bauer, Andrew John Macintosh and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information, peer review file, description of additional supplementary files, supplementary data 1, supplementary data 2, supplementary data 3, supplementary data 4, supplementary data 5, supplementary data 6, supplementary data 7, reporting summary, source data, source data, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Schreurs, M., Piampongsant, S., Roncoroni, M. et al. Predicting and improving complex beer flavor through machine learning. Nat Commun 15 , 2368 (2024). https://doi.org/10.1038/s41467-024-46346-0
Download citation
Received : 30 October 2023
Accepted : 21 February 2024
Published : 26 March 2024
DOI : https://doi.org/10.1038/s41467-024-46346-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Translational Research newsletter — top stories in biotechnology, drug discovery and pharma.

RSC Advances
Controllable fabrication of coni bimetallic alloy for high-performance electromagnetic wave absorption †.

* Corresponding authors
a Key Laboratory of Science and Technology on Wear and Protection of Materials, Lanzhou Institute of Chemical Physics, Chinese Academy of Sciences, Lanzhou, China E-mail: [email protected] , [email protected]
b Center of Materials Science and Optoelectronics Engineering, University of Chinese Academy of Sciences, Beijing, China
c State Key Laboratory of Solid Lubrication, Lanzhou Institute of Chemical Physics, Chinese Academy of Sciences, Lanzhou, China
d Laboratory of Clean Energy Chemistry and Materials, State Key Laboratory of Solid Lubrication, Lanzhou Institute of Chemical Physics, Chinese Academy of Sciences, Lanzhou, China
With the coming era of artificial intelligence (AI) dominated by high-tech electronics, developing high-performance microwave absorption materials (MAMs) is imperative to solve the problem of increasing electromagnetic inference and pollution. Herein, a metal–organic framework (MOF)-derived CoNi bimetallic alloy (CoNi/C) with an irregular rod-like structure is prepared by a thermal reduction method. Introducing the CoNi alloy facilitates the balance between conduction loss and polarization loss and forms good impedance matching, leading to excellent microwave absorption performance. Interestingly, the optimization of absorption performance can be further achieved by controllably modulating the molar ratio of Co and Ni (Co 2+ /Ni 2+ ). As expected, the obtained CoNi/C delivers excellent microwave absorption performance with a minimum reflection loss (RL min ) of −50.80 dB at 10.40 GHz and an effective absorption bandwidth (EAB) of 3.28 GHz (8.91–12.19 GHz) with a filler loading of 50 wt% at 2.0 mm. In addition, the CoNi/C can reach a maximum EAB of 4.77 GHz (12.99–17.76 GHz) at a low thickness of 1.5 mm, spanning nearly the entire Ku band. The CoNi 3 /C also exhibits an impressive RL min of −44.84 dB at 3.28 GHz in the S band. This work offers a novel strategy to modulate the magnetic/electric properties of MOF-derived MAMs.

Supplementary files
- Supplementary information PDF (1048K)
Transparent peer review
To support increased transparency, we offer authors the option to publish the peer review history alongside their article.
View this article’s peer review history
Article information
Download Citation
Permissions.
Controllable fabrication of CoNi bimetallic alloy for high-performance electromagnetic wave absorption
H. Xie, J. Li, R. Yang, J. Yang, T. Wang and Q. Wang, RSC Adv. , 2024, 14 , 9791 DOI: 10.1039/D3RA08896K
This article is licensed under a Creative Commons Attribution-NonCommercial 3.0 Unported Licence . You can use material from this article in other publications, without requesting further permission from the RSC, provided that the correct acknowledgement is given and it is not used for commercial purposes.
To request permission to reproduce material from this article in a commercial publication , please go to the Copyright Clearance Center request page .
If you are an author contributing to an RSC publication, you do not need to request permission provided correct acknowledgement is given.
If you are the author of this article, you do not need to request permission to reproduce figures and diagrams provided correct acknowledgement is given. If you want to reproduce the whole article in a third-party commercial publication (excluding your thesis/dissertation for which permission is not required) please go to the Copyright Clearance Center request page .
Read more about how to correctly acknowledge RSC content .
Social activity
Search articles by author, advertisements.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Int J Sports Phys Ther
- v.7(5); 2012 Oct
PUBLISHING YOUR WORK IN A JOURNAL: UNDERSTANDING THE PEER REVIEW PROCESS
Michael l. voight.
1 Belmont University, Nashville, TN, USA
Barbara J. Hoogenboom
2 Grand Valley State University, Grand Rapids, MI, USA
Manuscripts have been subjected to the peer review process prior to publication for over 300 years. Currently, the peer review process is used by almost all scientific journals, and The International Journal of Sports Physical Therapy is no exception. Scholarly publication is the means by which new work is communicated and peer review is an important part of this process. Peer review is a vital part of the quality control mechanism that is used to determine what is published, and what is not. The purpose of this commentary is to provide a description of the peer review process, both generally, and as utilized by The International Journal of Sports Physical Therapy . It is the hope of the authors that this will assist those who submit scholarly works to understand the purpose of the peer review process, as well as to appreciate the length of time required for a manuscript to complete the process and move toward publication.
INTRODUCTION
Manuscripts have been subjected to the peer review process prior to publication for over 300 years. The Royal Societies of Edinburgh and London first began seeking help from their membership with the selection process of articles for their publication in the early to mid‐18 th century. 1 Over time, other professional societies adopted the practice of peer review, however, as the process was introduced it was often disorganized and in most cases depended upon the chief editor. In the middle of the 20 th century, the peer review process became more widespread and standardized. 2 The main reason for the increased use of the peer review process is rooted in two main factors. The first of these is the proliferation of manuscripts. In the past, editors of new (and existing) journals often had to struggle to collect enough manuscripts to fill the pages of their journals and as such did not need to be selective. Subsequently, as the need for evidence‐based practice has evolved, submissions to scientific journals have increased to the point where editors need to be much more selective in what gets published in their journals. The second reason for the increased use of the peer review process is the explosion of new information and technology. Areas of expertise have expanded to become more specialized and sophisticated. Because of this, editors were no longer able to be experts in all areas and had to seek opinions and advice from others. 1 , 2 Currently, the peer review process is used by almost all scientific journals. The International Committee of Medical Journal Editors (ICMJE) defines peer review as: “[Peer review is] the critical assessment of manuscripts submitted to journals by experts who are not part of the editorial staff”. 3 The purpose of this clinical commentary is to provide a description of the peer review process, both generally, and as utilized by The International Journal of Sports Physical Therapy (IJSPT) . It is the hope of the authors that this will assist those who submit scholarly works to understand the purpose of the peer review process, as well as to appreciate the length of time required for a manuscript to complete the process and move toward publication.
WHAT SHOULD PEER REVIEW DO?
Scholarly publication is the means by which new work is communicated and peer review is an important part of this process. Peer review is an important part of the quality control mechanism that is used to determine what is published, and what is not. In the medical community, most scholarly work or research will not be seriously considered until it has been validated by peer review. Furthermore, the peer review process acts as a filter for interest and relevance to the field being targeted by a journal. Therefore, peer review should serve several purposes: 4
- Has the research that is being reported been carried out well with no flaws in the design or methodology?
- Ensure that the work is reported correctly, with acknowledgement of the existing body of work.
- Ensure that the results presented have been interpreted correctly and all possible interpretations considered.
- Ensure that the results are not too preliminary or speculative, but at the same time not block the sharing of innovative new research and theories.
- The relevance of the article to the specific clinical practice – select work that will be the greatest interest to the readership
- The interest of the topic to the clinical reader
- The presentation and understandability of the article itself
- Generally improve the quality and readability of a publication.
- 3. To check against malfeasance within the scientific and clinical community.
- 4. Provide editors with evidence to make judgments as to whether articles meet the selection criteria for their particular publication.
The main functions of the peer review process are to help maintain standards and ensure that the reporting of research work is as truthful and accurate as possible. Peer review contributes to the ongoing process used by individual clinicians to assess what information to believe and what to view with skepticism. This occurs because individual clinicians with varied levels of experience know that a peer reviewed, published manuscript has been reviewed and deemed worthy by others, often with greater or more varied experience than they possess. While most clinicians have the ability to critically read a research manuscript, they cannot be expected to be experts in all areas and make judgments about topics about which they know little. 5
THE PEER REVIEW PROCESS
The peer review process is similar for all journals, with some variation expected between journals. The procedure described here is the process used by IJSPT with manuscript submissions. Once an author submits a manuscript through the online submission process, it is automatically logged in and checked to make sure that the submission is complete and has been prepared according to the IJSPT submission instructions. At this time a receipt of manuscript acknowledgement is sent to the author to let them know that their manuscript has been received. Each manuscript is then read by an editor (either individually or in consultation) to assess its suitability for the journal according to the guidelines determined by the editorial policy. This is an important step to ensure that (1) the content falls within the scope of the journal, (2) the manuscript follows editorial policy and procedural guidelines, and (3) that it does not contain an unacceptable level of overlap with manuscripts that are already in press. A manuscript could be rejected without additional review for one or more of the previous reasons, and the author notified.
While manuscripts can be rejected without involving additional reviewers, they cannot be accepted for publication without additional review. So if a manuscript is not rejected when first received, it is then sent out for review to a minimum of two additional reviewers who are part of the journal's cadre of reviewers. Review by Associate Editors or staff may compliment this process. Within the medical and scientific communities, debate continues as to the precise form that a peer review should take. The closed review process is the traditional form of peer review adopted by most journals. One prominent area of contention is the subject of blinding. The most common model seems to be the single‐blinded review, in which the reviewer's identities are withheld from the authors but the reviewers are aware who wrote the paper they are evaluating. 6 This system has been heavily criticized for having the potential for bias because work originating from certain authors, institutions, or geographic regions may be treated more or less critically. The second type of blinding is the double‐blind review. With a double‐blind review the identity of the authors is also masked during the review process. Both the authors and the reviewers are unaware of each other's identity. This type of review has been popularly endorsed in author surveys and is the model employed by the IJSPT. 6 While the double‐blind process does appear to be a much fairer method of assessment as compared to the single blind review, this peer review process does have some limitations. Manuscripts that draw heavily on the submitting authors previous research may be difficult to mask effectively while still giving the reviewers the information they need to evaluate the study thoroughly. 6 , 7 , 8 Since the reviewers are often content experts within a given topic area, they may get enough clues from the citations in the manuscript and/or from their knowledge of the work going on in that topic area to hypothesize as to whom the author may be. Therefore, although it has been suggested that blinding reviewers to author identity leads to better opinions and reviews, this assertion has not been proven in trials. 9 , 10 Much can be done to help with this problem through careful attention to the manner in which earlier work is referenced in a paper, although some authors may intentionally make their identity easier to discern if they feel their reputation (and citing their previous publications liberally) will garner better treatment from the reviewers.
Once reviewers are chosen and they accept their review assignment, the real process begins. Most reviewers use some form of checklist that covers some or all of the considerations offered in Appendix 1. Note that this checklist is best utilized with papers that are submitted in the category of Original Research, and different criteria or salient points for assessment may be utilized for other types of submissions such as Case Reports, Clinical Commentaries, and Clinical Suggestions.
The reviewers return their recommendations and reports to the editor (via the online submission system), who assesses them collectively, and then makes a decision, either on his or her own or in consultation with other editors on whether to reject the manuscript (either outright or with encouragement to resubmit), to withhold judgment pending major or minor revisions, to accept it pending satisfactorily completed revisions, or to accept it as written. Rarely, if ever, is a manuscript accepted as written! For manuscripts accepted pending revision, the authors must submit a revised manuscript that will go through all or some of the stages above. Once a manuscript has been revised satisfactorily (more than one revision may or may not be allowed) it will be accepted and put into the production process to be prepared for publication. An outline of this process can be seen in Figure 1 . Despite the apparent simplicity in this process, the actual steps may be quite elaborate and involve a number of people and alternative procedures, thus requiring substantial time to complete.

A graphic display of the “path” a manuscript takes after submission to The International Journal of Sports Physical Therapy.
While the peer review process is unlikely to change the basic nature of a given submission, in many cases the authors may add analysis or results, clarify thoughts or parameters, revise the statistical testing methods, increase the number of subjects, or lengthen the time of clinical follow‐up in response to reviewer's requests. Most typically, thoughtful comments provided by reviewers lead to improvements in the presentation of the work in several ways: clarity in writing and descriptions are enhanced, relevant literature is discussed more thoroughly, limitations of methodology are acknowledged, and broad or over‐reaching conclusions are moderated. This can only happen when knowledgeable reviewers take time to participate in the peer review process and evaluate submissions with care and sensitivity. The editors and reviewers of IJSPT are committed to utilization of a stringent yet fair review process in order to assist those who submit scholarly work for publication.
APPENDIX 1: SAMPLE REVIEW GUIDELINES
Title: Does it accurately reflects the purpose, design, results, and conclusions of the study?
Abstract: Does it correctly and succinctly summarize the salient points of the study?
Introduction: Does it provide adequate background and rationale for performing the study?
- Why is study being done? Identify controversy?
- Is the functional, biological, and/or clinical significant of the topic established.
- Strengths and limitations described such that a need for further study is established.
- Is the literature discussed in the introduction directly related to the purpose of the manuscript and necessary to introduce the topic?
- Is it clear how the experimental approach to be used in the present study is likely to yield more definitive or unique insight than previous studies?
- Does it clearly state or imply the study hypothesis(es) or null hypothesis?
- Are the outcomes to be measured clearly described in the introduction or methods section?
- Does the introduction adequately introduce the purpose of the manuscript in a logically compelling way?
- Is a clear and strong rationale provided for the importance of this manuscript?
Study design and methodology: Is the sample described in appropriate detail; procedures and data analysis described clearly and in sufficient detail?
- IRB approved?
- Type of study described? (RCT, Cohort, Case controlled, Case report, etc)
- Do the methods address the purpose?
- Are there factors not controlled between the groups: (list)
- Is the study: Prospective or Retrospective
- Is it reproducible?
- If not, do the authors provide a proper (peer reviewed) reference that would provide such details?
- Is there a rationale for the experimental design?
- Identified and appropriate to answer question?
- Informed consent obtained?
- Inclusion / exclusion criteria
- Where enough subjects studied to detect a difference?
- What methods were used?
- If subjects were not randomized, were subjects and controls equivalent?
- Was the randomization assignment concealed from both patients and healthcare staff until recruitment was complete and irrevocable?
- Will the subject population allow extensive or rather limited generalizability?
- Were the subjects asked to participate in the study representative of the entire population from which they were recruited?
- Were those subjects who were prepared to participate representative of the entire population from which they were recruited?
- Were the staff, places, and facilities where the patients were treated representative of the treatment the majority of patients received
- Was an attempt to blind study subjects to the intervention they have received?
- Single‐blind (patient)
- Double‐blind (patient & investigator)
- Any analysis that had not been planned at the outset of the study should be clearly indicated.
- Therapeutic intervention clearly defined? Treatments should be clearly described.
- Standard accepted measurement instrument or method? (ie. Universal?)
- Are metrics provided for standard instruments, procedures, or methods?
- Reproducible?
- Are the details as to how the data were derived (calculated) adequately explained so that they can be confirmed by the reviewer and reproduced by future investigators?
- Is it clear how the data will be interpreted to either support or refute the hypothesis?
- Minimal_____ Average_____
- Is mechanism of follow‐up described?
- Loss to follow‐up reported?
Soundness of the Results: the outcome of the statistical analysis are presented appropriately and interpreted accurately.
- Is there excessive variability in one or more of the measurements for a particular condition compared with others?
- Are the main findings of the study clearly described? Simple outcome data should be reported for all major findings so that the reader can check the major analyses and conclusions.
- Are they relevant to the study or research problem?
- Are data presented that was not described in the methods?
- Statistical results tell statistical significance?
- Actual results tell clinical significance?
- Was compliance with the intervention reliable?
- Are all the figures and tables needed?
- Are the tables and figures properly labeled with titles and the correct units?
- Is the scaling of the figures appropriate and unbiased?
- Was randomization successful?
- Appropriate test(s) chosen?
- Have the actual probability values been reported rather than <0.05 for the main outcomes except were the probability value is less than 0.001.
- Have adjustments been made for multiple comparisons?
- Does the study provide estimates of the random variability in the data for the main outcomes?
- Does the analysis adjust for different lengths of follow‐up of patients, or in case‐controlled studies, is the time period between the intervention and outcome the same for cases and controls?
- Remember: failure to show a difference is NOT the same as showing that there is no difference – may be a lack of power.
- Have all the important adverse events that may be a consequence of the intervention been reported?
- How do the group differences or responses shown compare with the measurement variability?
Discussion and Conclusion: The implications of the study are consistent with the purpose, methods, and data analysis.
- Is the significance of the present results described?
- Is it clear how the findings extend previous knowledge in a meaningful way?
- Does it point out weaknesses/limitations of the study?
- Performance
- Detection (measurement)
- Transfer (loss of follow‐up)
- Does it point out the strengths of the study?
- Discuss similarities and differences
- Are important experimental observations from previous reports described in the context of the present results?
- Does it distinguish author opinion from the conclusions
- Do the authors support their statements with appropriate references?
- Do the authors discuss their data in a manner that provides insight beyond that presented in previous sections?
- Is there any other way to interpret and/or explain the data other than that suggested by the authors?
- Is it based on the data described in the results?
- Key conclusions adequately supported by the experimental data?
- Does it point out the clinical significance of the conclusions?
- Do authors make suggestions as to how the results of their study need to be extended in the future to learn more about the issue in question?
- Does it stray beyond the boundaries of the study?
Organization and Style
- Is the material presented, without excessive jargon?
- Are all the graphs or charts needed?
- Was the paper well written, properly organized, and easy to follow?
- Was proper grammar, spelling, and punctuation used throughout?
- Should manuscript be shortened?
- Should manuscript be more comprehensive?
- Are the major references included?
- Are all references cited completely and in the desired format of the journal
- References chosen directly relate to the study?
- Avoids secondhand or abstract reference sources?
- Are all references cited correctly in text, e.g superscripted following punctuation.
Overall Significance and Suitability
- Was the information presented in an open‐minded and objective manner?
- Is the experimental question significant?
- Overall method is valid?
- Results are properly presented and believable?
- Conclusions are reasonable on the basis of the results obtained?
- Does manuscript contain new findings or ideas?
- If not, does it present old material better?

Login | Register
- Author Guidelines
- Editorial Team
A Review of Towards an Ecocritical Theatre: Playing the Anthropocene
Author: Iris Goode-Middleton (Hampton University)
Book Reviews
- View Harvard Citation Style
- View Vancouver Citation Style
- View APA Citation Style
- Download RIS
- Download BibTeX
This book review looks Mohebat Ahmadi’s Toward’s an Ecocritical Theatre: Playing the Anthropocene. Ahmadi’s book presents a compelling exploration of the intersection between theatre and the ecological challenges of the Anthropocene. Each chapter delves into the comprehensive analysis of key theatrical works and practices that explore the ways theatre can serve as a powerful medium for engaging and responding to the environmental crises of our time.
Keywords: Ecocritical theatre, towards an Ecocritical theatre, environmental theatre, Mohebat Ahmadi, theatre in the Anthropocene
Goode-Middleton, I., (2024) “A Review of Towards an Ecocritical Theatre: Playing the Anthropocene”, the Black Theatre Review 2(2), 44-47. doi: https://doi.org/10.2458/tbtr.5877
Downloads: Download PDF
7 Downloads
Published on 26 mar 2024, peer reviewed, creative commons attribution-noncommercial 4.0, harvard-style citation.
Goode-Middleton, I. (2024) 'A Review of Towards an Ecocritical Theatre: Playing the Anthropocene', the Black Theatre Review . 2(2) :44-47. doi: 10.2458/tbtr.5877
Show: Vancouver Citation Style | APA Citation Style
Vancouver-Style Citation
Goode-Middleton, I. A Review of Towards an Ecocritical Theatre: Playing the Anthropocene. the Black Theatre Review. 2024 3; 2(2) :44-47. doi: 10.2458/tbtr.5877
Show: Harvard Citation Style | APA Citation Style
APA-Style Citation
Goode-Middleton, I. (2024, 3 26). A Review of Towards an Ecocritical Theatre: Playing the Anthropocene. the Black Theatre Review 2(2) :44-47. doi: 10.2458/tbtr.5877
Show: Harvard Citation Style | {% trans 'Vancouver Citation Style' %}
Non Specialist Summary
This article has no summary
IMAGES
VIDEO
COMMENTS
The key characteristic of scientific writing is clarity. Before submitting a manuscript for publication, it is highly advisable to have a professional editing firm copy-edit your manuscript. An article submitted to a peer-reviewed journal will be scrutinized critically by the editorial board before it is selected for peer review.
Communicating research findings is an essential step in the research process. Often, peer-reviewed journals are the forum for such communication, yet many researchers are never taught how to write a publishable scientific paper. In this article, we explain the basic structure of a scientific paper and describe the information that should be included in each section. We also identify common ...
This article aims to provide an overview of the form, structure, and reporting standards for different types of papers, with a focus on writing for publication in peer-reviewed journals. It will also provide a summary of the different considerations to be made by authors selecting the right journals in which to publish their research, and offer ...
The introduction section should be approximately three to five paragraphs in length. Look at examples from your target journal to decide the appropriate length. This section should include the elements shown in Fig. 1. Begin with a general context, narrowing to the specific focus of the paper.
Introduction. Publishing in the peer-reviewed literature is essential to advancing science and its translation to practice in public health (1,2).The public health workforce is diverse and practices in a variety of settings ().For some public health professionals, writing and publishing the results of their work is a requirement.
Abstract. Communicating research findings is an essential step in the research process. Often, peer-reviewed journals are the forum for such communication, yet many researchers are never taught how to write a publishable scientific paper. In this article, we explain the basic structure of a scientific paper and describe the information that ...
The publication process explained. The path to publication can be unsettling when you're unsure what's happening with your paper. Learn about staple journal workflows to see the detailed steps required for ensuring a rigorous and ethical publication. Your team has prepared the paper, written a cover letter and completed the submission form.
Look at examples from your target journal to decide the appropriate length. This section should include the elements shown in Fig. 1. Begin with a general context, narrowing to the specific focus of the pa-per. Include five main elements: why your research is im-portant, what is already known about the topic, the gap.
Free 1 hour monthly How to Get Published webinars cover topics including writing an article, navigating the peer review process, and what exactly it means when you hear "open access.". Join fellow researchers and expert speakers live, or watch our library of recordings on a variety of topics. Browse our webinars.
Christopher W. Schmidt, the Editor of Law & Social Inquiry, offers advice on publishing in a peer-reviewed journal. Your Abstract Is More Important Than You ThinkLaw & Social Inquiry (LSI) regularly receives strong manuscripts with weak abstracts. First impressions are important, and the first impression you'll make with our editorial team ...
B ACKGROUND. The publication of original research in a peer-reviewed and indexed journal is the ultimate and most important step toward the recognition of any scientific work.However, the process starts long before the write-up of a manuscript. The journal in which the author wishes to publish his/her work should be chosen at the time of conceptualization of the scientific work based on the ...
Peer Review, Research*. Periodicals as Topic. Publishing*. The basis of a manuscript is the research question, which is reported within a standard publication structure. The 'Background' section clarifies the question. The 'Methods' section describes what was done in the study. The 'Results' section describes the data observed and the analysis ...
Peer review by invited experts, suggested by the authors, takes place openly after publication. An article remains published regardless of the reviewers' reports. Authors are encouraged to respond openly to the peer review reports, which are published with the article, and can publish revised versions of their article, if they wish.
Trustworthy, peer-reviewed, open access journals maintain the same rigorous editorial standards as traditional peer-reviewed journals. However, the open access model has led to the proliferation of publishers, known as predatory publishers, that exist only to make money. Their publications claim to be peer reviewed but rarely are.
Think about structuring your review like an inverted pyramid. Put the most important information at the top, followed by details and examples in the center, and any additional points at the very bottom. Here's how your outline might look: 1. Summary of the research and your overall impression. In your own words, summarize what the manuscript ...
2. Double-blind peer review: Neither author nor reviewers know the identity of the other. 3. Open peer review: The identities of authors and reviewers are known. In this model, reviews are also sometimes published along with the paper. 4. Post-publication peer review: In some models, particularly for
8) Pick the right journal: it's a bad sign if you don't recognise any of the editorial board. Check that your article is within the scope of the journal that you are submitting to. This seems ...
The Pee Review process, or the refereeing process, is a complex and necessary step in the publishing process. However, the main purpose of this thorough process is to bring valuable academic journal articles in the world that other Researchers and Authors can use, access, share, and expand upon them. A thorough and complex peer review process ...
When peer reviewing, it is helpful to think from the point of view of three different groups of people: Authors. Try to review the manuscript as you would like others to review your work. When you point out problems in a manuscript, do so in a way that will help the authors to improve the manuscript. Assume that the authors are doing their best ...
Deep Resources Engineering is a gold open access, peer-reviewed journal dedicated to the rapid publication and global dissemination of the latest findings in the field of deep engineering. The journal bridges the gap between research scientists and engineers who work in diverse disciplines related to deep resources engineering.
Peer review timelines depend on article type and vary widely across journals. The rules of transparent publishing necessitate recording manuscript submission and acceptance dates in article footnotes to inform readers of the evaluation speed and to help investigators in the event of multiple unethical submissions.
Summary. Researchers recently reviewed 69 articles focused on the management implications of the Covid-19 pandemic that were published between March 2020 and July 2023 in top journals in ...
ACM, the Association for Computing Machinery, has relaunched Communications of the ACM (CACM), the organization's flagship magazine, as a web-first publication, accessible to everyone without charge. First published in 1958, CACM is one of the most respected information technology magazines. Providing news, expert commentary, and peer-reviewed research, CACM straddles the lines between a ...
A peer review file is available. Additional information Publisher's note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Transition metal-based catalysts are commonly used for water electrolysis and cost-effective hydrogen fuel production due to their exceptional electrochemical performance, particularly in enhancing the efficiency of the oxygen evolution reaction (OER) at the anode. In this study, a novel approach was developed for
Doping active agents into metal-organic frameworks (MOFs) is widely sought after owing to its potential to enhance adsorption and photocatalytic efficiency, surpassing the potential of bare frameworks. This study incorporated a catalytically active NS-ligand (1,2-benzisothiazolin-3-one) into a very stable and porou
With the coming era of artificial intelligence (AI) dominated by high-tech electronics, developing high-performance microwave absorption materials (MAMs) is imperative to solve the problem of increasing electromagnetic inference and pollution. Herein, a metal-organic framework (MOF)-derived CoNi bimetallic alloy (C
Furthermore, the peer review process acts as a filter for interest and relevance to the field being targeted by a journal. Therefore, peer review should serve several purposes: 4. 1. To help select quality articles for publication (filter out studies that have been poorly conceived, designed, and executed) with the selection being based upon ...
This book review looks Mohebat Ahmadi's <i>Toward's an Ecocritical Theatre: Playing the Anthropocene. </i>Ahmadi's book presents a compelling exploration of the intersection between theatre and the ecological challenges of the Anthropocene. Each chapter delves into the comprehensive analysis of key theatrical works and practices that explore the ways theatre can serve as a ...